
Arch 基础
gpu层次结构图如下
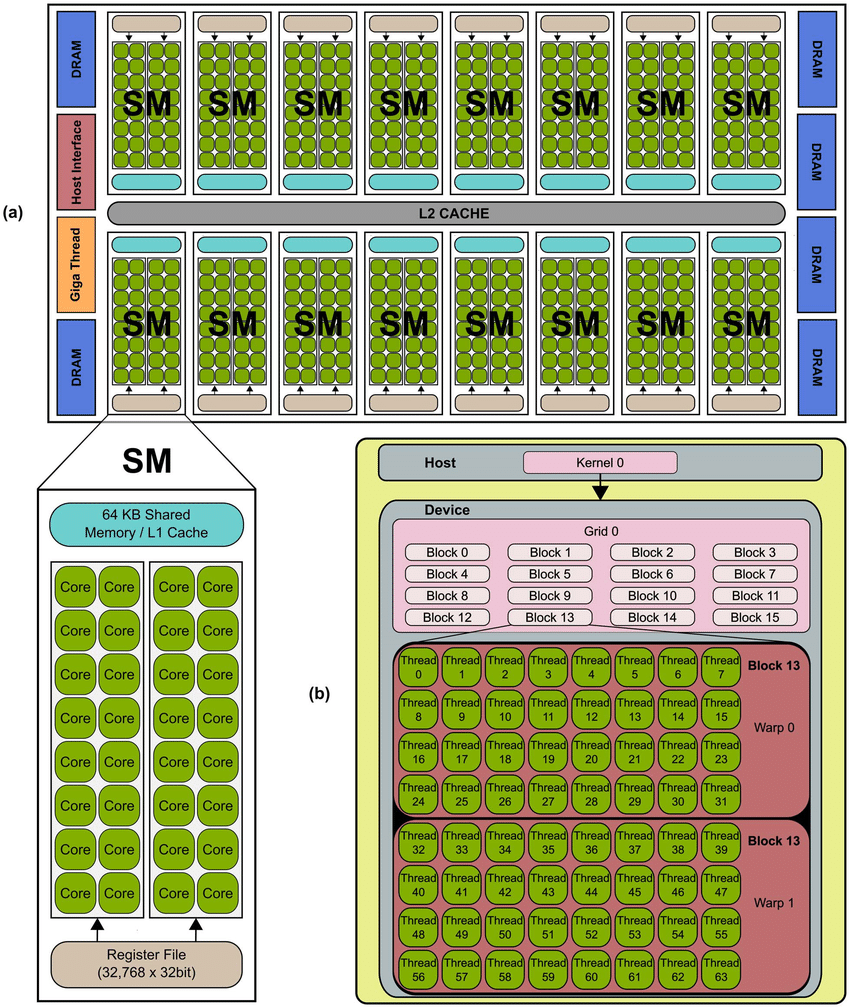
thread, block, grid
1.关系
一个kernel有一个grid,一个grid有多个block,一个block有多个thread(按warp)分组
每个Grid可以最多创建65535个block,每个Block最多512个thread
workgroup其实是onencl的术语,对应cuda就是逻辑上的block。
2.访存层次
访问层次上,thread操作register(local memory),block操作share memory,grid操作global ram,所以 thread 一次只能取一个寄存器的值。
越高访存层次的访问latency越小
每个 bank 一次只能处理一个访问,当多条 thread 访问的数据处于同一个 bank,则会发生 bank conflict。
访存合并是将多个 内存访问请求 合并成较少的 内存访问请求 ,但每个线程还是只访问一个元素数据。
一个 warp 中的 thread 在同一时间执行相同的指令。所以访存连续后,可以加大单时间内访问的数量
一个block内的所有thread通过share memory(这个share mem 就是负责该block的L1 Cache)来交换数据。不同block之间的thread是无法通信的
Hopper 架构增加了 SM-to-SM 的线路,所以多个 block 理论上可以共同使用负责它们的 SM 的 shared mem。
3.warp
block中的thread又会以warp(线程束)为单位,对thread进行分组组织。
warp大小当前一般是32。比如说如果有一个block 里有128 个thread 的话,就会被分成四组warp,第0-31 个thread 会是warp 1、32-63 是warp 2、64-95是warp 3、96-127 是warp 4。而如果block 里面的thread 数量不是32 的倍数,那他会把剩下的thread独立成一个warp。
warp 内的 thread 在同一时间执行相同的指令,逻辑上和 SIMD 相似。
SM是负责完成 block 计算任务的执行单元。warp 分组的动作是由 SM 自动进行的。
对于计算密集型kernel,4-warp配置通常是最常用/首选的。8-warp配置可能会在prologue或epilogue阶段引入一些延迟。对于非常小的GEMM问题,可以尝试2-warp或1-warp配置。
一个SM 可以同时处理多个线程块block,当其中有block 的所有thread 都处理完后,他就会再去找其他还没处理的block 来处理。
CTA, CGA
- CTA:就是 thread block
cooperative thread array:
CTA(Cooperative Thread Array):CTA是一个线程组,由一组线程组成,这些线程可以在GPU上的多个处理器中并行执行。CTA中的线程可以协同工作,通过共享内存等方式进行通信和协作。CTA通常是在CUDA编程模型中使用的概念,它是将工作任务划分为较小的线程块以便并行执行的基本单元。
一个CTA通常由多个warp组成。一个CTA的线程数量可以是32的倍数(例如,CTA可以有32、64、96等线程)。CTA内的线程被划分为一组一组的warp,每个warp中的线程同时执行相同的指令。每个warp中的thread若访问的内存区域连续,那么这些访问行为可以被coalesce。
- CGA:一组 CTA
cooperative grid array:它是一组CTA的集合,可以在GPU上协同工作。CGA可以用于更大规模的并行计算,将任务划分为多个CTA进行执行,并且CTA之间可以通过全局内存进行通信和同步。
triton-lang中有一个关于优化 CGA 中 CTA 行为的pass
- thread block cluster
一个Block的Thread配较少时->执行慢
一个Block的Thread配较多时->SM利用率低,且block可使用的smem有限,当负责的任务规模较大时,则需要使用gdram,使得IO成为瓶颈
以block为粒度来处理任务阻碍运行效率,需要提供更大粒度的线程组
thread block cluster是更大粒度的线程组,其中的线程组可以访问分布在不同block的smem,这些smem称为 distributed smem
smem和SM的L1Cache共用一块物理空间,但Cache是不可见的,而smem是程序员可见的,这是SM私有(L2 Cache是共用的)。但若thread block cluster的block在多个SM上运行,就需要特殊的结构实现SM的smem共享。
SM
1.架构
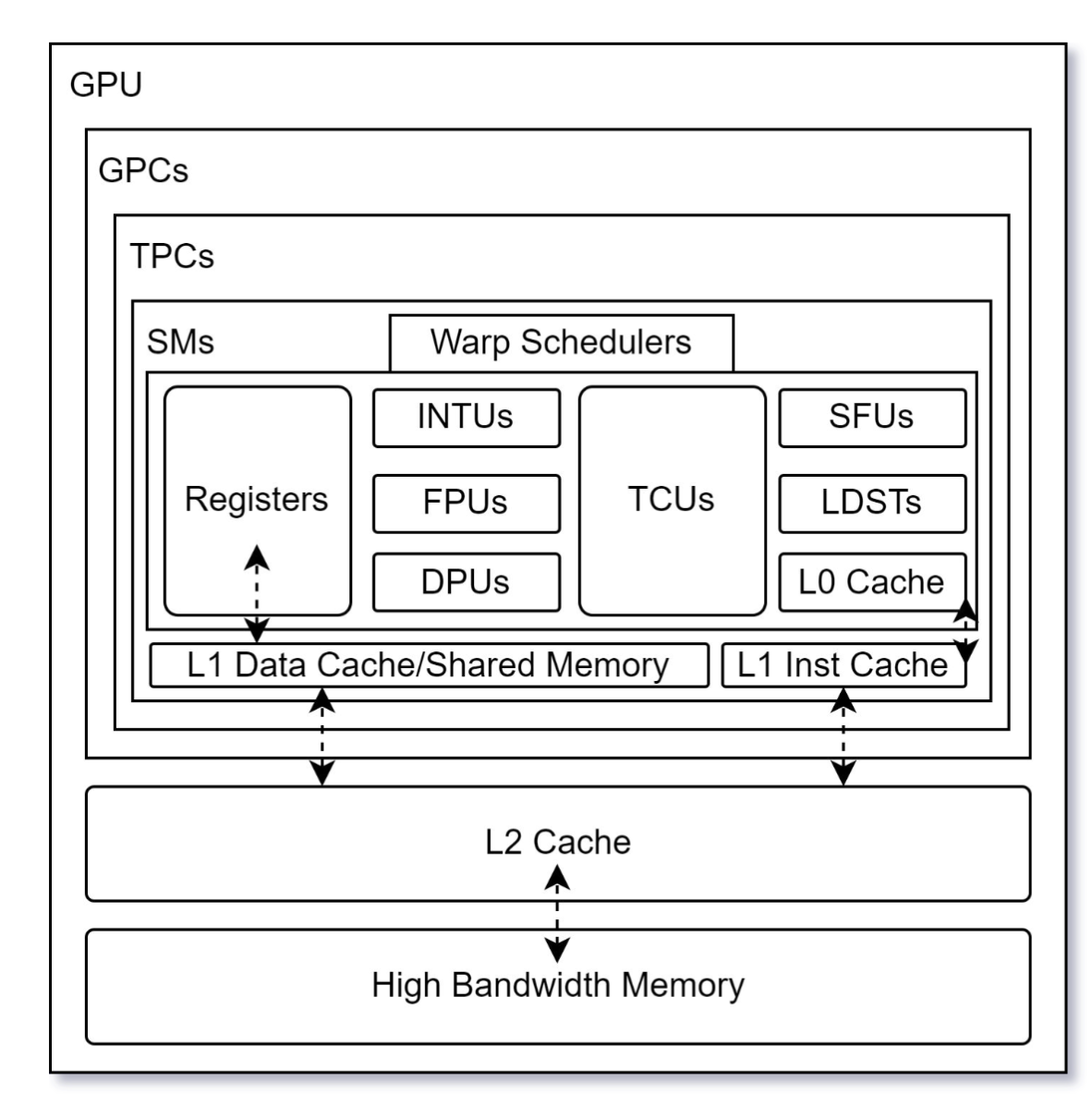
- INTU 整数计算单元
- FPU 单精度浮点计算单元
- DPU 双精度浮点计算单元
- SFU 特殊functio单元
- LDST load-store单元
2.smem, L1 cache
每个 SM 都有独立的 smem, constant cache, register mem,SM之间共享 L2 Cache 和 gdram。 SM(流式多处理器) 中的处理单位称为 SP(流示处理器)。
自 Volta 架构后,SM 中的 smem 和 L1 Cache 就合并成一块 memory block 了。
如此程序员就可以自行配置 smem 的大小,在放存密集且连续的场景下(例如matmul),smem大一些性能更好。但是 smem 和 L1 Cache的总大小是一定的。
L1 Cache保留的原因:L1在某些场景下也是必要的,例如以 sparse computing 中;smem是很快会用到的,L1是从dram上取来的,cache是防止低速访存必要的,smem能防止污染cache。
smem用来thread之间共享,由程序员显式管理,不适用复杂、不可预测的场景。L1 Cache由硬件自动管理。
Hopper 架构中引入了 SM-to-SM 的高速网络,实现了 SM 之间的 smem 互相访问。这为 Thread Block Cluster 提供了编程支持。
Thread Block Cluster 的提出是因为以 thread block 为粒度执行任务阻碍运行效率。需要提供更大粒度的线程组。所以一个 thread block cluster 中包含多个 thread block,其中所有 thread 都可以访问负责该 thread block cluster 计算的 SM 群的 smem,这些 smem 一起称为 distributed smem。
3.warp scheduler
每个 warp 会被分配到一个 warp scheduler 上,warp scheduler 可以在不同的 warp 之间切换。当某个 warp stall 时,可以通过切换 warp 来掩盖访存开销(在访存时换另一个warp上),来减少 stall 时间。
比如 Ampere 4 个 warp scheduler,所以 thread block 一般线程数不会少于 128 个,256 个比较常用,因为可以切换 warp 来减少 stall 的时间。
每个 warp scheduler 有两个 instruction dispatch,每个 cycle 都可以向当前处于其上的 warp 发送两条指令。
但是要求这两条指令满足:数据独立、不同的硬件单元、前序指令已经完成发射
memory unit
DMA, TMA
- Direct Memory Access 用于提高数据传输
- Tensor Memory Accelerator 专门设计用来张量数据的传输
data access
1.gdram-smem 数据访问的流程:
(1)虚拟地址转物理地址
(2)ROB申请空间,以便于(乱序执行时)提交时获得正确的目的地址
(3)发送总线请求到LLC
(4)LLC命中则返回,失败则从gdram中找
2.memory-coalecse
如果一个 warp 需要处理的数据连续时,就可以将多个 thread 的内存访问请求合并成一个或者较少个内存传输请求,而不是每个 thread 单独进行内存访问。
pass 前后都是每条 thread 单独发送自己的内存请求,这些请求被合并后由于 LSU(Load/Store Uint) 发送请求到硬件。
3.layout swizzling
smem 中数据是以 bank 的形式组织的,每个 bank 可以单独处理一个内存访问请求。如果多个内存访问请求都指向同一 bank,则会产生 bank-conflict。
所以需要 layout-swizzling 对数据进行重新排列,确保warp在同一时刻的多个内存访问请求处于不同的 bank。
layout-swizzling 是通过软件算法改变地址映射关系,使得内存访存模式和物理存储布局更匹配。 logic layout -> swizzle mapping -> physical layout
IR
- PTX 和 SSAS
ptx 和 sass 的区别在于,一个表示虚拟,一个表示实际。 ptx 指令只定义了指令的功能,而 sass 指令表明了针对不同代架构的底层实现。
cubin 是硬件二进制指令。