
常见指标
- TPS: Token Per Second
- MFU: Model FLOPs Utilization
- MaaS: Model as a service
- TTFT: Time To First Token
- TPOC: Time Per Output Token
attention
1.QK的相似度计算不用除以模长
点积直接表现了向量之间的相似性,在后序softmax计算中,越大的点积就能越突出(越大的权重)。
如果除以模长,就变成了余弦相似度,忽略了向量长度因素的影响。
在self-attention和MHA中,Q和K都是通过变换而来的,保留模长的信息保证了在训练中可以改变变换Q和K的变换参数。
所以处理模长当前只增加了计算复杂度,并未带来显著的收益。
2.除以 $\sqrt{d}$ 得作用
缩放因子用于平衡不同维度的影响,使得softmax输出更加平滑,防止输出过于尖锐,导致梯度消失/爆炸。
选择 $\sqrt{d}$ 而不是 $d$ 作为缩放因子,是一种权衡,既保证了点积的值不会太大,也保证了softmax中有一定区分度。
3.softmax激活函数
softmax会将最后的结果归一化,相当于概率分布(落在0~1之间),全部的结果加起来为1。
这反应的是每个Key对Query的重要性。
其他激活函数不能满足这两点,或者要增加额外的计算,而且softmax梯度计算简单。
4.mask
attention(decoder) 中的 mask:因为是对初始输入一个个计算,当对token_i进行计算时,需要舍弃掉其后的token,所以需要mask来做舍去的行为(softmax时会认为-inf的部分是0),以排除干扰
prefill 阶段的输入是已知的完整序列,模型需要同时看到所有 token 来提取全局信息。所以一般不需要 mask。
而 decode 阶段是自回归,需要限制模型只能看到当前 token 及其之前的 token 来生成下一个 token,因此会使用 mask (例如 casual mask)。
5.kvcache
kvcache只适用于decoder self-attention结构,因为decoder结构有casual_mask,self-attention的KV需要按步更新。
以空间换时间。

- 传统注意力计算时,需要将当前时刻的
Q去乘以过去所有时刻的K,如果没有KV Cache,每一次就需要重新计算KV(通过输入和权重矩阵计算)。 - 每一轮计算只依赖于当前的 Q_i,以及之前所有时刻的 K、V,使用kv cache后,就不需要重新计算之前的KV
- Q Cache:从单request来讲是不需要Q cache的,但从整体系统而言,分析每次 request 的 Q 相关性(例如问一样的问题),也是对系统有意义的。
GEMM 降级到 GEMV 后,还想继续用上 tensor core,可以增加计算的并行,将运算拼接成一个GEMM。
window attn(sliding windows):每个token只和包含本身在内的前n个token做attn(使用前几次decode的kvcache),这样kvcache就可以只存一个window的个数。更早的token信息可以跨层流动,就像cnn中的感受野(输出只跟一些输入有关)
window attn 是在 Mixtral 中提出的,Mixtral 中Rotary的意思就是:通过某种规则,将Cache中的数据旋转回正确的位置,以便能正确做Attention。因为cache每次都在更新,重新写入,所顺序是不符合期望的。
kv cache存储会造成大量碎片化 -> 使用分页管理(page):将每个序列的键值划分为块,采用非连续的存储分配方案,减少空间浪费
6.MQA、GQA、MLA
- MQA:所有 Attention-Head 共享一组 KV Cache
- GQA:一组 KV Cache 支持一个 Group 的 Q
- MLA:不再做 QK 的乘积,直接使用投影表示。无法使用RoPE位置编码,而使用ALIBI这种。
网络结构
Transformer
Transformer的基本单位就是一层block,包含 Masked-Self-Attention + FFN:
- Attention 捕捉 token序列内部的依赖关系
- FFN (又称MLP)对每个位置的特征进行更深层次的加工和抽象,从而提升模型的整体表达能力
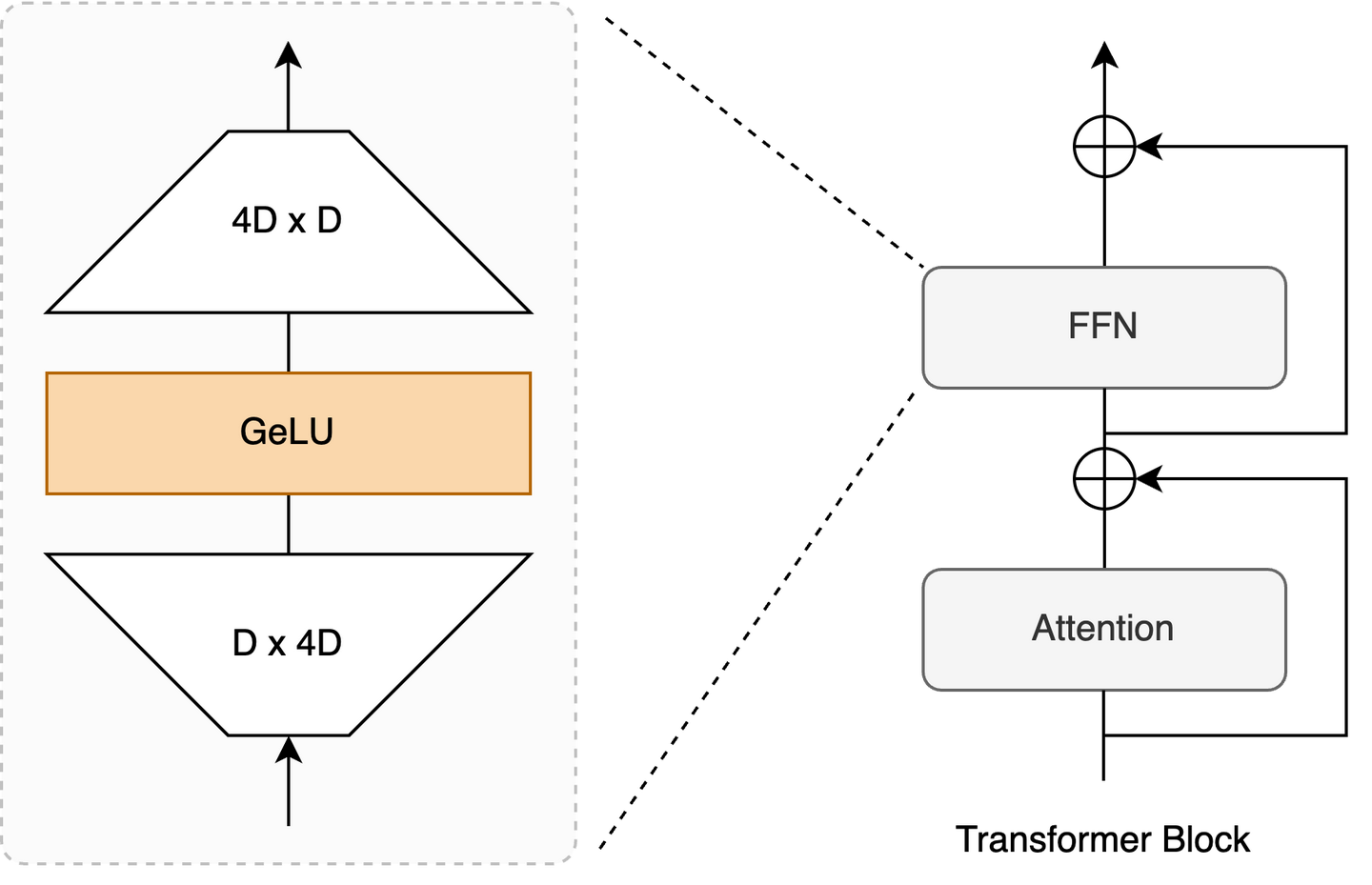
FFN的参数中存放着大量training过程中学习到的比较抽象的knowledge,是transfomer结构的表征核心。FFN 的设计目标是增强模型的表达能力,使其能够学习更复杂的函数映射,所以输出一般不会为低秩的激活值。
低秩表示矩阵中的信息存在冗余,,如果一个神经网络层的激活值或权重矩阵具有低秩特性,我们可以使用低秩分解等方法来近似这个矩阵,从而减少模型的参数量和计算量,实现模型压缩和加速。
MoE
MoE 其实就是一组参数量更小的 FFN 结构,attention 的结果将通过 gate network 挑选出 两组 “experts”(即参数量更小的 FFN)来分别处理该 token,并通过加法方式融合两组 “experts” 的输出。
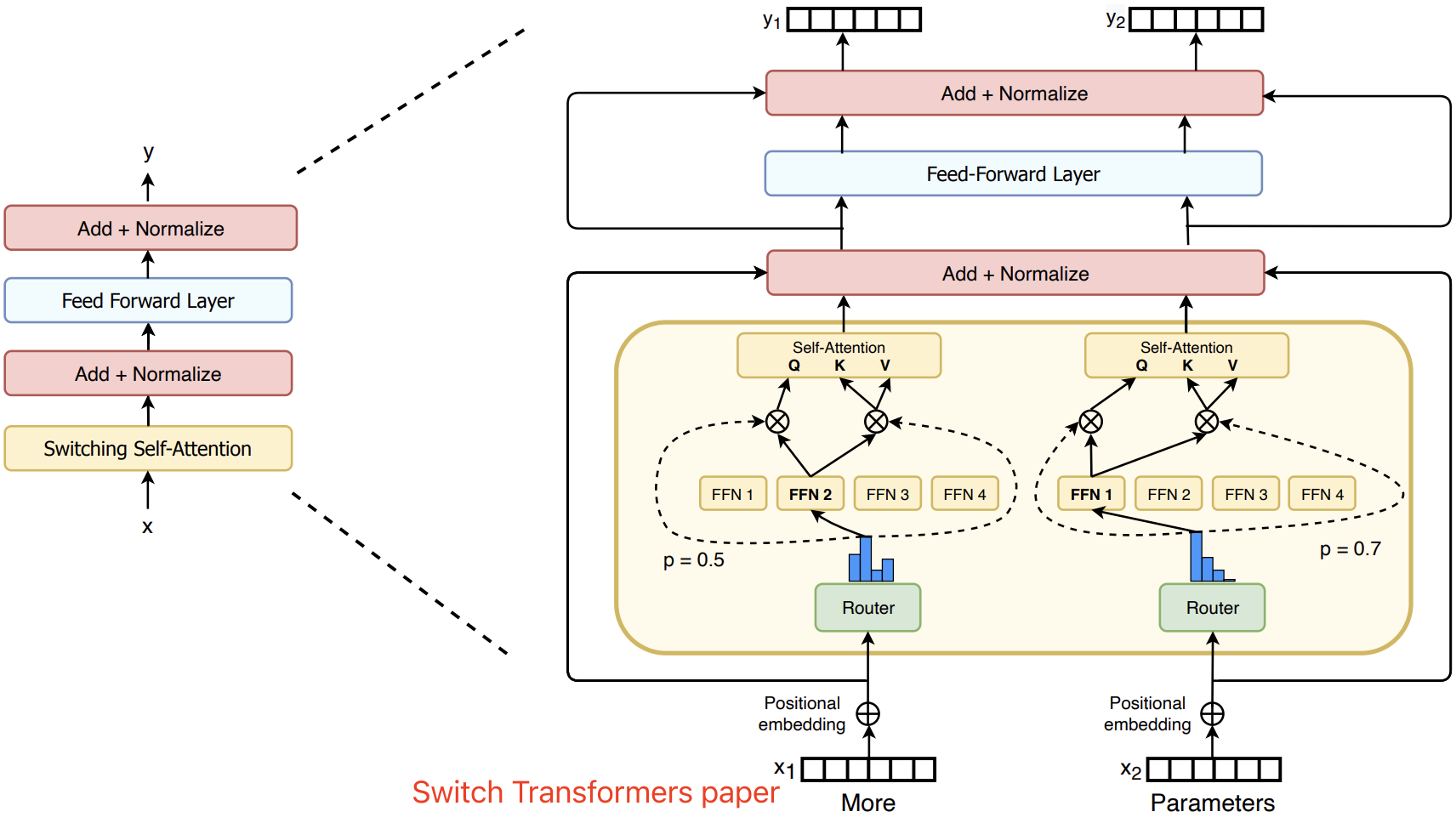
DeepSeekMoe相比普通MoE的改进:
- shared expert: 1个,即 Gate 网络,用于捕捉通用的全局信息,将用于计算每个 token 与所有 router expert 的兼容性得分(用于反应和专家的契合程度),并选择 topK 个 router expert
- router expert: 被选中的专家各自对 token 进行独立处理,输出会根据 Gate 网络给出的得分权重进行加权聚合
ep下的moe中每个layer有两次all2all2,第一次是在gate后选择对应的expert,称为dispatch;第二次是在被选择expert完成计算后,将计算结果进行加权,称为compute。
若将attention和moe都进行tp,且attention分给m个设备,expert分给n个设备,那么两次all2all的通信就会变成m2n和n2m。
训练概念
pretrain、SFT、RLFH
pretrain 是在大量无标签文本数据上进行模型训练的过程。模型通过预测下一个token,不断调整自身参数。
SFT全称Supervised Fine-Tuning,是在 pretrain 之后,对 response 行为进行预测调整。
RLHF全称 Reinforcement Learning from Human Feedback,让模型生成的内容更符合人类偏好。
pretrain 可以理解为积累专业知识, SFT 可以理解学会执行特定任务,RLHF 是让模型做更符合人类期望的事情。
将一个基础模型训练成领域模型的步骤
要将基础模型改为领域特定模型,通常需要以下步骤:
(1) 领域数据收集,并进行数据预处理
(2) 使用领域数据进行 Pretraining
(3) 进行 SFT(Supervised Fine-Tuning),让其在特定任务中表现得更好
(4) 训练 RM(Reward Modeling),来评估生成内容的质量,去除得分低的
(5) RLHF使用强化学习结合人类反馈,调整模型以生成更符合需求的输出。
(6) 评估、验证、部署、监控
推理概念
prefill 和 decode
推理过程分为prefill和decode,只不过decode是逐个生成token,不能像prefill那样大段prompt做并行。
- prefill:模型理解用户的输入,需要吃下完整一段数据
- 两个目标:生成 Prompt token 时的 KV Cache + 生成首个 token
- Q K V 序列长度相同,一般是 计算密集型(计算瓶颈)
- 常使用 Flash-Attention 算子优化这方面
- decode:模型逐token生成回答(续写)
- 在原始序列上继续(续写)生成 token
- Q 一般远小于 K 和 V,是 访存密集型(访存瓶颈),每次生成 token 都要去读已经存储的 KV Cache
- 常使用 Page-Attention 的技术去优化 KV Cache 的存储。
- 优化
- FlashAttention: batch、head 维度并行,依赖高并发使得 btach 足够大
- FlashDecoding: sequence维度并行,需要将 kv Cache 划分成 chunk,分开计算,然后再 chunk-wise reduce。减小内存开销
融合式和分离式:prefill 和 decode 一起做害死 prefill 和 decode 分离
- 融合式策略:由于 prefill 和 decode 相互干扰,优先级难以确定,难以同时满足所有需求的 TTFT 和 TPOT 需求
- 分离式策略:Prefill实例做完后将kvcache传输到Decode实例上,额外的存储开销和通信开销。prefill 实例上的存储相比 decode 实例的压力要小很多
compute bound / compute bound
| 任务类型 | compute bound | memory bound |
|---|---|---|
| 卡选择 | 算力 成本更低的卡 | 带宽 陈本更低的卡 |
| 优化重点 | 计算和通讯overlap | 算子融合,减小launch开销 |
- Prefill 阶段:
- 不管是 Dense 模型,还是 MoE 模型,当序列不是特别短时,基本都是 Compute Bound 问题,能充分发挥 GPU 算力。
- Decoding 阶段:
- Dense 模型:
- Attention:无参数的 Softmax$(QK)V$ 近似 Grouped GEMV 操作,算术强度不高,近似为 “Q Head/ KV Head”,明显的 Memory Bound,所以无法充分利用 GPU 算力。
- FFN:
- 当 Batch Size 比较小时,FFN 是明显的 Memory Bound。
- 当 Batch Size 增加到“算力/显存带宽”时基本达到 Compute Bound。
- MoE 模型:
- Attention:与上述 Dense 模型类似。
- FFN:与 Dense 模型类似,只不过要达到 Compute Bound 需要更大的 Batch Size。这主要是每次只激活个别专家,假设激活专家与总专家的比例是 1/16:
- Dense 模型可能在 Batch Size 为 156(A100:312T FLOPS / 2TB/s = 156)即可以达到 Compute Bound。
- MoE 模型需要 Batch Size 为 156*16=2496 才能达到 Compute Bound,并且由于负载不均,可能会更加严重。
decoder only
当前LLM的架构基本都是decoder only,好处是训练效率高:方便并行(特别是流水并行),加大参数量更简单
在线推理和离线推理
- 在线推理
- 需求:实时请求,高并发
- 技术:动态批处理(合理调整batch,连续批处理),内存优化(kv cache管理)
- vLLM
- 离线推理
- 需求:极致性能,单卡内存
- 技术:量化、静态批处理(等待到一定量的请求后一起发出,等所有的请求都完成后才释放硬件资源)
- TensorRT-LLM
投机采样(Speculative Decoding)
(1)用小模型做自回归连续采样生成n个token
(2)将生成的n个token和前缀拼接在一起,送入大模型执行一次前向
(3)根据结果判断是接受小模型的结果还是重新进行(1)
计算量是不变的,但大模型内n个会同时参与计算,计算访存比显著提升
分布式
- DP: 一般在batch维度(独立的样本数据)拆分,将独立的数据拆开
- TP: 将weight拆分到不同的设备,在不同设备上计算一部分activation,再通过通信原语给合并起来
- PP: 拆出mini-batch,每个设备负责一部分
- 1F1B(最后一个设备算完1F后就算1B,减少activation所占显存), 1F1B Interleaved
- CPP(Circal Pipeline Parallel) 是PP的一种,通过引入“循环”机制,使得数据在流水线中循环流动。允许new batch在old batch计算完成之前进入流水线。
- SP: 切分Sequence,序列指的是具有时间或顺序关系的数据,例如文本中的单词序列、时间序列数据
- 当sequence被分到不同devie上,需要让一定的通信来传递顺序信息(attention需要关注到前一段seq的最后一个token)
- 将序列划分为多个子序列时,每个子序列之间保留一定的重叠部分。
- 设备之间通过通信机制(如 All-Gather 或 All-Reduce)交换边界 token 的信息,以计算跨设备的注意力分数。
- 当sequence被分到不同devie上,需要让一定的通信来传递顺序信息(attention需要关注到前一段seq的最后一个token)
- CPP: Chunk Prefill Pipeline
量化
量化:低位宽数据代替高位宽数据,激活值很难量化(存在异常值,导致量化后精度损失严重,所以量化系统不能全模型统一,按照量化难易程度进行分块)
常见的两种形式:block-wise 和 tile-wise
- block-wise
- 将数据分成大块,所有块共享量化参数
- 存储开销小,计算复杂度低
- tile-wise
- 将数据为为多个小块,每个小块使用单独的量化参数
- 对于数据分布不均匀的场景能更好地防止精度下降