
相比 ttir 专注表示计算逻辑(硬件无关),ttgir 表示和硬件相关的计算表示。新增的 op 例如:
- alloc_tensor : tensor<128x32xf32, #share> :申请shared memory
- insert_slice_async: 往 shared memory 上 insert 一个 slice,语意上类似
tensor.insert_slice,底层对应的cp.async指令 - async_commit_group: 底层对应的 cp.async.commit_group 指令,就是将前面的所有 cp.async 指令打包到一起执行
- async_wait {num}: 底层对应的 cp.async.wait_group 指令,也就是等待前面 num 个 cp.async-groups 执行完
- cnovert_layout: 改变 tensor 的 layout
这些 op 在后续 transforms(pipeline, prefetch等) 中将很重要。本文主要介绍 ttir 到 ttgir 的 conversion,主要源码在 createConvertTritonToTritonGPUPass 中,需要使用来自 kernel 的 numWarps, threadsPerWarp, numCTAs 参数,这些信息会随着 TritonGPUTypeConverter 在 conversion 的过程中被用到。
- layout
- Conversion
- analysis(e.g. AxisInfo) 后序在 transforms 文中讲解
layout
include/triton/Dialect/TritonGPU/IR/TritonGPUAttrDefs.td
TritonGPU Dialect 这一层的 IR的 tensor 表示将带有 Layout 的 Attr,该 Attr 定义了 Data 是如何被 Thread 并行处理。这种layout attr在lowering过程中被传递。
自 [RFC] To generalize TritonGPU dialect for GPU of different vendors 后, TritonGPU Dialect 中的 Layout Attribute 正式统一为下图:
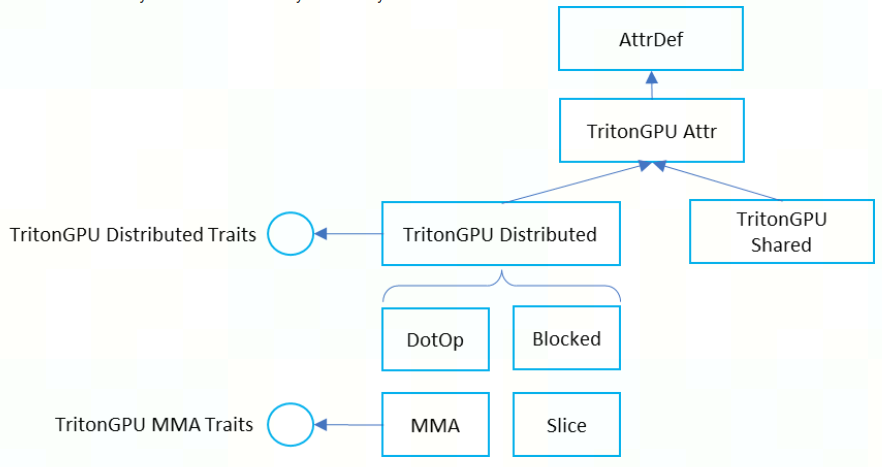
当前最重要的也是 distributed layout 和 shared layout。
cta layout
描述 CGA 中的 CTA 布局。主要有 CTAsPerCGA、CTASplitNum、CTAOrder 三个属性。
一个 tensor 被分给 CTAPerCGA 个 thread blocks 处理,每个 CTA 负责 tensor_shape / CTASplitNum 的数据。
例如对于一个 matmul AxB=C, 操作数 A = [M, K], B = [K, N], C = [M, N]:
- A、B、C 的
CTAsPerCGA相同,设为 [SplatM, SplatN] CTASplitNum:A = [SplatM, 1], B = [1, SplatN], C = [SplatM, SplatN]
由于 CGA 是在 Hopper(sm90) 架构才引入的,所以该 Attr 在大部分的情况都是直接使用默认的 CTAsPerCGA = CTASplitNum = [1...1]。
shared layout
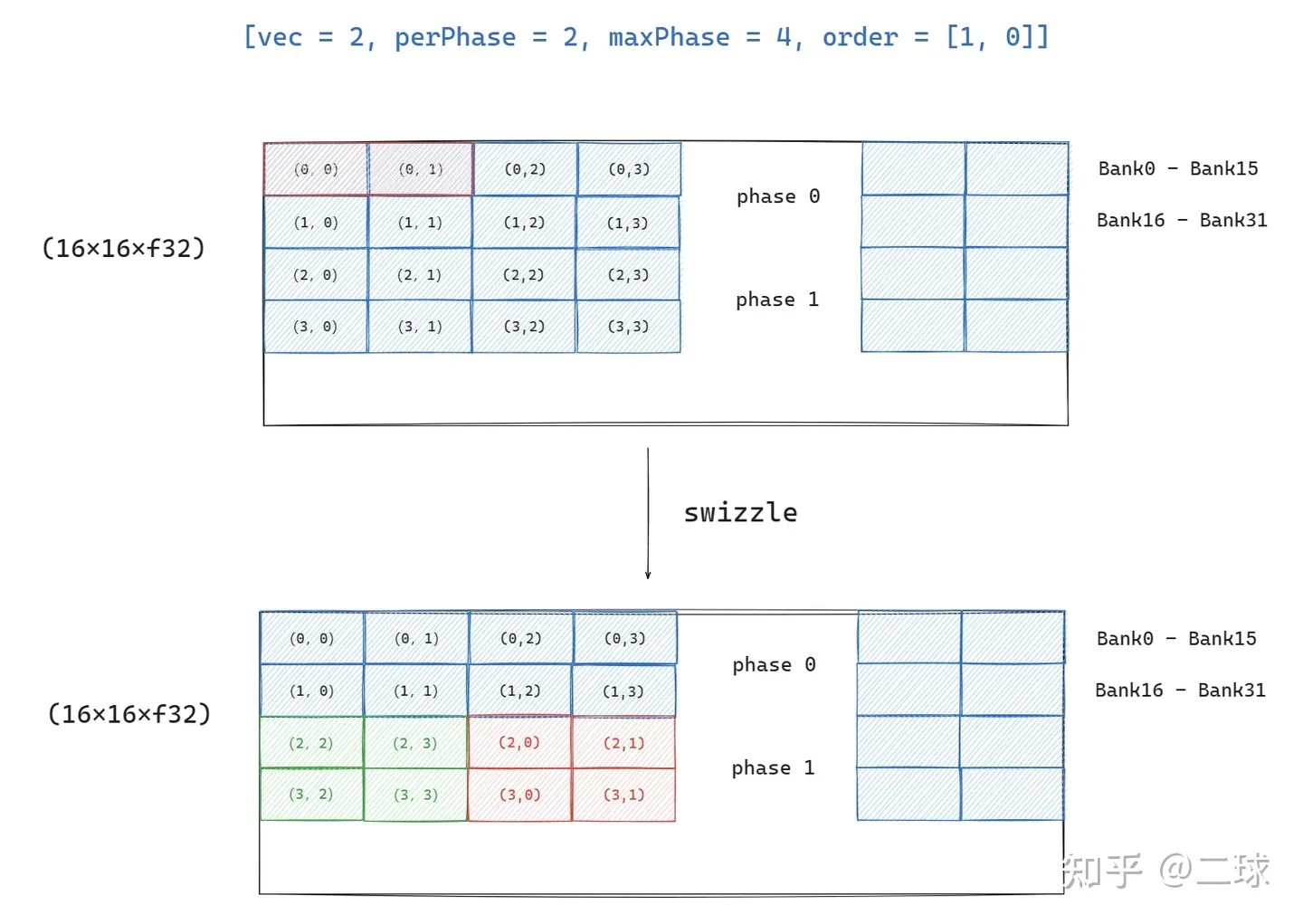
表示了一种 tensor 编码模式,用于指导如何进行 swizzle,使得不同 thread 在访问 tensor(on shared memory) 上的元素时尽量避免 bank conflict。
swizzle:调整数据在 shared memory 上的存储位置,保证 thread 访问时不出现 bank conflict。
该layout中主要对象为:
- vec:同行的元素进行swizzle时,连续vec个为一组
- perPhase:一次 swizzling phase 处理的 row 数。连续的 perPhase 行用相同的swizzle方法
- maxPhase:swizzling phase的个数
- order:表明哪一个为主序,[1, 0] 为行主序,同行相邻元素地址连续
- hasLeadingOffset:默认为false,Hopper MMAv3为true
swizzle 最基础的方法就是地址 与 phase_id 进行 xor。
假设现在有4x4个元素需要存到 shared memory 上去,存放的初始地址为:
[r, c] 上对应的元素为 (r:c)。
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)]
[ (1:0),(1:1),(1:2),(1:3)]
[ (2:0),(2:1),(2:2),(2:3)]
[ (3:0),(3:1),(3:2),(3:3)]]
- #shared<{vec=1, perPhase=1, maxPhase=4, order=[1,0]}>
不同行中的地址与不同的参数 xor。out[r][c] = in[r][c ^ r]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0 (xor with 0)
[ (1:1),(1:0),(1:3),(1:2)] // phase 1 (xor with 1)
[ (2:2),(2:3),(2:0),(2:1)] // phase 2 (xor with 2)
[ (3:3),(3:2),(3:1),(3:0)]] // phase 3 (xor with 3)
- #shared<{vec=1, perPhase=2, maxPhase=4, order=[1,0]}>
相邻 2 (perPhase) 行中的地址用相同的参数xor。out[r][c] = in[r][c ^ (r / 2)]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0 (xor with 0)
[ (1:0),(1:1),(1:2),(1:3)] // phase 0 (xor with 0)
[ (2:1),(2:0),(2:3),(2:2)] // phase 1 (xor with 1)
[ (3:1),(3:0),(3:3),(3:2)]] // phase 1 (xor with 1)
- #shared<{vec=1, perPhase=1, maxPhase=2, order=[1,0]}>
每隔 2(maxPhase) 行,地址用相同的参数xor。out[r][c] = in[r][c ^ (r % 2)]
phase相同, swizzle 的行为相同。
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0 (xor with 0)
[ (1:1),(1:0),(1:3),(1:2)] // phase 1 (xor with 1)
[ (2:0),(2:1),(2:2),(2:3)] // phase 2 (xor with 0)
[ (3:1),(3:0),(3:3),(3:2)]] // phase 3 (xor with 1)
- #shared<{vec=2, perPhase=1, maxPhase=4, order=[1,0]}>
相邻 2(vec) 元素为一组,进行 xor。 out[r][c] = in[r][(c / 2) ^ r) * 2 + (c % 2)]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0
[ (1:2),(1:3),(1:0),(1:1)] // phase 1
[ (2:0),(2:1),(2:2),(2:3)] // phase 2
[ (3:2),(3:3),(3:0),(3:1)]] // phase 3
- #shared<{vec=2, perPhase=2, maxPhase=4, order=[1,0]}>
out[r][c] = in[r][(c / 2) ^ (r % 2)) * 2 + (c % 2)]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)]
[ (1:0),(1:1),(1:2),(1:3)]
[ (2:2),(2:3),(2:0),(2:1)]
[ (3:2),(3:3),(3:0),(3:1)]]
distributed layout
distributed layout 使用映射函数描述整个 tensor 的访问模式。映射函数(layout function)会将特定的Tensor交给特定的Thread去处理(即一个layout描述整个tensor的访问模式),达到一个distribution的效果
layout function 说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 计算公式
\mathcal{L}(A)[i_d] = L[(i_d + k_d*A.shape[d]) % L.shape[d]] \forall k_d such as i_d + k_d*A.shape[d] < L.shape[d]
- 举例:A 是需要访问的数据,L是当前线程的布局
A = [x x x x x x x x]
[x x x x x x x x]
L = [0 1 2 3 ]
[4 5 6 7 ]
[8 9 10 11]
[12 13 14 15]
// L(i, j) = {...} 用来描述数据 (i, j) 被哪些CUDA线程访问
L(A) = [ {0,8} , {1,9} , {2,10}, {3,11}, {0,8} , {1, 9} , {2, 10}, {3, 11},
{4,12}, {5,13}, {6,14}, {7,15}, {4,12}, {5, 13}, {6, 14}, {7, 15} ]
- 计算过程
d = 0 或 1, 0 <= k_0 <= 3,0 <= k_1 <= 3,A.shape = [2, 8], L.shape = [4, 4]
那么负责访问 A[1, 3] 的线程为:
(i_0 + k_0 * A.shape[0]) % L.shape[0] = (1 + [0, 3] * 2) % 4 = 1 或 3
(i_1 + k_1 * A.shape[1]) % L.shape[1] = (3 + [0, 3] * 8) % 4 = 3
所以负责访问 A[1, 3] 的线程是 L[1, 3] 和 L[3, 3]。
distributte layout 将信息分为4个维度:
- CTAs Per CGA:在 hopper 上才有用,因为 hopper 架构首次引入了 SM-to-SM
- Warps Per CTA:CTA 内 warp 的布局(对应
warpsPerCTA) - Threads Per Warp:warp 内 thread 的布局(对应
threadsPerWarp) - Values Per Thread:一个 thread 需要处理多少元素(对应
sizePerThread)
常用函数方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 继承自 cta layout
SmallVector<unsigned> getCTAsPerCGA() const;
SmallVector<unsigned> getCTAOrder() const;
SmallVector<unsigned> getCTASplitNum() const;
SmallVector<unsigned> getWarpsPerCTA() const;
SmallVector<unsigned> getWarpOrder() const;
SmallVector<unsigned> getThreadsPerWarp() const;
SmallVector<unsigned> getThreadOrder() const;
SmallVector<unsigned> getSizePerThread() const;
// sizePerThread * threadsPerWarp * warpsPerCTA
SmallVector<unsigned> getShapePerCTATile(ArrayRef<int64_t> tensorShape = ArrayRef<int64_t>()) const;
std::optional<LinearLayout> toLinearLayout(ArrayRef<int64_t> shape) const;
block layout
最常见的 layout,结合 AxisInfoAnalysis 获得 load 和 store 的访存行为,再用来访存合并(memory coalescing),使得访存行为更加高效。
An encoding where each warp owns a contiguous portion of the target tensor. This is typically the kind of data layout used to promote memory coalescing in LoadInst and StoreInst.
- 基础概念
例如:#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
- sizePerThread = [1, 4]:每个线程处理的 连续排布 数据数目
- threadsPerWarp = [4, 8]: warp内线程的布局
- warpsPerCTA = [1, 1]:thread block内warp的布局
- order = [1, 0]:先访问dim1,再访问dim0
该BLock访存模式:每行由8个thread负责访问,每个thread会访问连续4个元素,所以一次能处理(1x4x1, 8x4x1) = (4, 32)规模的shape。如下:
1
2
3
4
5
6
7
$ triton-tensor-layout -l "#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>" -t "tensor<4x32xf16>"
# T0:0, T0:1, T0:2, T0:3 表示 T0 一次处理4个连续数组成的块
Print layout attribute: #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
[[ T0:0, T0:1, T0:2, T0:3, T1:0, T1:1, T1:2, T1:3, T2:0, T2:1, T2:2, T2:3, T3:0, T3:1, T3:2, T3:3, T4:0, T4:1, T4:2, T4:3, T5:0, T5:1, T5:2, T5:3, T6:0, T6:1, T6:2, T6:3, T7:0, T7:1, T7:2, T7:3]
[ T8:0, T8:1, T8:2, T8:3, T9:0, T9:1, T9:2, T9:3, T10:0, T10:1, T10:2, T10:3, T11:0, T11:1, T11:2, T11:3, T12:0, T12:1, T12:2, T12:3, T13:0, T13:1, T13:2, T13:3, T14:0, T14:1, T14:2, T14:3, T15:0, T15:1, T15:2, T15:3]
[ T16:0, T16:1, T16:2, T16:3, T17:0, T17:1, T17:2, T17:3, T18:0, T18:1, T18:2, T18:3, T19:0, T19:1, T19:2, T19:3, T20:0, T20:1, T20:2, T20:3, T21:0, T21:1, T21:2, T21:3, T22:0, T22:1, T22:2, T22:3, T23:0, T23:1, T23:2, T23:3]
[ T24:0, T24:1, T24:2, T24:3, T25:0, T25:1, T25:2, T25:3, T26:0, T26:1, T26:2, T26:3, T27:0, T27:1, T27:2, T27:3, T28:0, T28:1, T28:2, T28:3, T29:0, T29:1, T29:2, T29:3, T30:0, T30:1, T30:2, T30:3, T31:0, T31:1, T31:2, T31:3]]
但若输入op的shape为(8, 32),那么让每个thread处理两个连续块即可,即第一个thread处理(0, 0:3), (4, 0:3)两个块。
1
2
3
4
5
6
7
8
9
10
$ triton-tensor-layout -l "#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>" -t "tensor<8x32xf16>"
Print layout attribute: #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
[[ T0:0, T0:1, T0:2, T0:3, T1:0, T1:1, T1:2, T1:3, T2:0, T2:1, T2:2, T2:3, T3:0, T3:1, T3:2, T3:3, T4:0, T4:1, T4:2, T4:3, T5:0, T5:1, T5:2, T5:3, T6:0, T6:1, T6:2, T6:3, T7:0, T7:1, T7:2, T7:3]
[ T8:0, T8:1, T8:2, T8:3, T9:0, T9:1, T9:2, T9:3, T10:0, T10:1, T10:2, T10:3, T11:0, T11:1, T11:2, T11:3, T12:0, T12:1, T12:2, T12:3, T13:0, T13:1, T13:2, T13:3, T14:0, T14:1, T14:2, T14:3, T15:0, T15:1, T15:2, T15:3]
[ T16:0, T16:1, T16:2, T16:3, T17:0, T17:1, T17:2, T17:3, T18:0, T18:1, T18:2, T18:3, T19:0, T19:1, T19:2, T19:3, T20:0, T20:1, T20:2, T20:3, T21:0, T21:1, T21:2, T21:3, T22:0, T22:1, T22:2, T22:3, T23:0, T23:1, T23:2, T23:3]
[ T24:0, T24:1, T24:2, T24:3, T25:0, T25:1, T25:2, T25:3, T26:0, T26:1, T26:2, T26:3, T27:0, T27:1, T27:2, T27:3, T28:0, T28:1, T28:2, T28:3, T29:0, T29:1, T29:2, T29:3, T30:0, T30:1, T30:2, T30:3, T31:0, T31:1, T31:2, T31:3]
[ T0:4, T0:5, T0:6, T0:7, T1:4, T1:5, T1:6, T1:7, T2:4, T2:5, T2:6, T2:7, T3:4, T3:5, T3:6, T3:7, T4:4, T4:5, T4:6, T4:7, T5:4, T5:5, T5:6, T5:7, T6:4, T6:5, T6:6, T6:7, T7:4, T7:5, T7:6, T7:7]
[ T8:4, T8:5, T8:6, T8:7, T9:4, T9:5, T9:6, T9:7, T10:4, T10:5, T10:6, T10:7, T11:4, T11:5, T11:6, T11:7, T12:4, T12:5, T12:6, T12:7, T13:4, T13:5, T13:6, T13:7, T14:4, T14:5, T14:6, T14:7, T15:4, T15:5, T15:6, T15:7]
[ T16:4, T16:5, T16:6, T16:7, T17:4, T17:5, T17:6, T17:7, T18:4, T18:5, T18:6, T18:7, T19:4, T19:5, T19:6, T19:7, T20:4, T20:5, T20:6, T20:7, T21:4, T21:5, T21:6, T21:7, T22:4, T22:5, T22:6, T22:7, T23:4, T23:5, T23:6, T23:7]
[ T24:4, T24:5, T24:6, T24:7, T25:4, T25:5, T25:6, T25:7, T26:4, T26:5, T26:6, T26:7, T27:4, T27:5, T27:6, T27:7, T28:4, T28:5, T28:6, T28:7, T29:4, T29:5, T29:6, T29:7, T30:4, T30:5, T30:6, T30:7, T31:4, T31:5, T31:6, T31:7]]
当 sizePerThread = [2, 4] 时也可以一次处理完(8, 32)的数据,与上面那种执行两边的方法区别上,layout在 row 上会连续。
1
2
3
4
[[ T0:0, T0:1, T0:2, T0:3, T1:0, T1:1, T1:2, T1:3, T2:0, T2:1, T2:2, T2:3, T3:0, T3:1, T3:2, T3:3, T4:0, T4:1, T4:2, T4:3, T5:0, T5:1, T5:2, T5:3, T6:0, T6:1, T6:2, T6:3, T7:0, T7:1, T7:2, T7:3]
[ T0:4, T0:5, T0:6, T0:7, T1:4, T1:5, T1:6, T1:7, T2:4, T2:5, T2:6, T2:7, T3:4, T3:5, T3:6, T3:7, T4:4, T4:5, T4:6, T4:7, T5:4, T5:5, T5:6, T5:7, T6:4, T6:5, T6:6, T6:7, T7:4, T7:5, T7:6, T7:7]
[ T8:0, T8:1, T8:2, T8:3, T9:0, T9:1, T9:2, T9:3, T10:0, T10:1, T10:2, T10:3, T11:0, T11:1, T11:2, T11:3, T12:0, T12:1, T12:2, T12:3, T13:0, T13:1, T13:2, T13:3, T14:0, T14:1, T14:2, T14:3, T15:0, T15:1, T15:2, T15:3]
...
- memory coalesce
一个简单的例子说明:
假如一个 warp 希望访问 128 个数(tensor<128xf16>),下面的 layout 会通过四次搬运完成:
1
#blocked_before = #blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
memory-coalesce 后将会让每个 thread 处理的数据更多,这样一次就可以搬运完成更能在后端映射成 vectorization 指令。
1
#blocked_after = #blocked<{sizePerThread = [4], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
MMA Layout 和 DotOperand Layout
用来指导 op 下降到特殊指令的 attr。
1.MMA Layout
表示 Tensor Core 中 MMA 指令结果的 data layout,一般可以直接对应到 PTX 指令中相应的数据排布需求。
和硬件相关很大,这里不展开
2.DotOperand Layout
表示 dotOp 的输入的 layout。主要包含 opIdx 和 parent 两个信息,
- opIdx :用来标识 dotOp 的操作数
- opIdx=0 表示 DotOp 的 $a
- opIdx=1 表示 DotOp 的 $b
- parent:决定了 DotOperand 的布局方式
- MMA Layout(如果 DotOp lower 到 MMA 指令)
- Blocked Layout(如果 DotOp lower 到 FMA 指令)
Slice Layout
Slice Layout 通过给定的 parent layout 和 dim 维度来压缩指(squeezing)定维度。
- 如果 dim = 0,则会将不同列的数据组合在一起形成新的 layout
- 如果 dim = 1,则会将不同行的数据组合在一起形成新的 layout
slice layout 在 tt.expand_dim 的 ttir-to-ttgir 转换中使用到了,看后文的例子更好理解。
linear layout
类似 CUTLASS v3 中的 CuTe Layout,在 PR 中第一次引入,用于表示生成 indices 的行为。
tools for layout
在 PR 中合入了一个可以打印 ttgir 上 layout 的工具 triton-tensor-layout,通过调用 getLayoutStr 来解析 RankedTensorType 中的 layout 信息,且当前已经支持了 shared layout 的 dump。例如:
- distribute layout
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ triton-tensor-layout -l "#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>" -t "tensor<16x16xf16>"
Print layout attribute: #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
# 每行用8个thread,每行中每个thread会负责连续的4个元素,但一行只有16个元素,所以4个thread就能遍历完一遍了
# 因此 T0 和 T4 都会访问第0行的前四个元素
[[ T0:0| T4:0, T0:1| T4:1, T0:2| T4:2, T0:3| T4:3, T1:0| T5:0, T1:1| T5:1, T1:2| T5:2, T1:3| T5:3, T2:0| T6:0, T2:1| T6:1, T2:2| T6:2, T2:3| T6:3, T3:0| T7:0, T3:1| T7:1, T3:2| T7:2, T3:3| T7:3]
[ T8:0| T12:0, T8:1| T12:1, T8:2| T12:2, T8:3| T12:3, T9:0| T13:0, T9:1| T13:1, T9:2| T13:2, T9:3| T13:3, T10:0| T14:0, T10:1| T14:1, T10:2| T14:2, T10:3| T14:3, T11:0| T15:0, T11:1| T15:1, T11:2| T15:2, T11:3| T15:3]
[ T16:0| T20:0, T16:1| T20:1, T16:2| T20:2, T16:3| T20:3, T17:0| T21:0, T17:1| T21:1, T17:2| T21:2, T17:3| T21:3, T18:0| T22:0, T18:1| T22:1, T18:2| T22:2, T18:3| T22:3, T19:0| T23:0, T19:1| T23:1, T19:2| T23:2, T19:3| T23:3]
[ T24:0| T28:0, T24:1| T28:1, T24:2| T28:2, T24:3| T28:3, T25:0| T29:0, T25:1| T29:1, T25:2| T29:2, T25:3| T29:3, T26:0| T30:0, T26:1| T30:1, T26:2| T30:2, T26:3| T30:3, T27:0| T31:0, T27:1| T31:1, T27:2| T31:2, T27:3| T31:3]
[ T32:0| T36:0, T32:1| T36:1, T32:2| T36:2, T32:3| T36:3, T33:0| T37:0, T33:1| T37:1, T33:2| T37:2, T33:3| T37:3, T34:0| T38:0, T34:1| T38:1, T34:2| T38:2, T34:3| T38:3, T35:0| T39:0, T35:1| T39:1, T35:2| T39:2, T35:3| T39:3]
[ T40:0| T44:0, T40:1| T44:1, T40:2| T44:2, T40:3| T44:3, T41:0| T45:0, T41:1| T45:1, T41:2| T45:2, T41:3| T45:3, T42:0| T46:0, T42:1| T46:1, T42:2| T46:2, T42:3| T46:3, T43:0| T47:0, T43:1| T47:1, T43:2| T47:2, T43:3| T47:3]
[ T48:0| T52:0, T48:1| T52:1, T48:2| T52:2, T48:3| T52:3, T49:0| T53:0, T49:1| T53:1, T49:2| T53:2, T49:3| T53:3, T50:0| T54:0, T50:1| T54:1, T50:2| T54:2, T50:3| T54:3, T51:0| T55:0, T51:1| T55:1, T51:2| T55:2, T51:3| T55:3]
[ T56:0| T60:0, T56:1| T60:1, T56:2| T60:2, T56:3| T60:3, T57:0| T61:0, T57:1| T61:1, T57:2| T61:2, T57:3| T61:3, T58:0| T62:0, T58:1| T62:1, T58:2| T62:2, T58:3| T62:3, T59:0| T63:0, T59:1| T63:1, T59:2| T63:2, T59:3| T63:3]
[ T64:0| T68:0, T64:1| T68:1, T64:2| T68:2, T64:3| T68:3, T65:0| T69:0, T65:1| T69:1, T65:2| T69:2, T65:3| T69:3, T66:0| T70:0, T66:1| T70:1, T66:2| T70:2, T66:3| T70:3, T67:0| T71:0, T67:1| T71:1, T67:2| T71:2, T67:3| T71:3]
[ T72:0| T76:0, T72:1| T76:1, T72:2| T76:2, T72:3| T76:3, T73:0| T77:0, T73:1| T77:1, T73:2| T77:2, T73:3| T77:3, T74:0| T78:0, T74:1| T78:1, T74:2| T78:2, T74:3| T78:3, T75:0| T79:0, T75:1| T79:1, T75:2| T79:2, T75:3| T79:3]
[ T80:0| T84:0, T80:1| T84:1, T80:2| T84:2, T80:3| T84:3, T81:0| T85:0, T81:1| T85:1, T81:2| T85:2, T81:3| T85:3, T82:0| T86:0, T82:1| T86:1, T82:2| T86:2, T82:3| T86:3, T83:0| T87:0, T83:1| T87:1, T83:2| T87:2, T83:3| T87:3]
[ T88:0| T92:0, T88:1| T92:1, T88:2| T92:2, T88:3| T92:3, T89:0| T93:0, T89:1| T93:1, T89:2| T93:2, T89:3| T93:3, T90:0| T94:0, T90:1| T94:1, T90:2| T94:2, T90:3| T94:3, T91:0| T95:0, T91:1| T95:1, T91:2| T95:2, T91:3| T95:3]
[ T96:0|T100:0, T96:1|T100:1, T96:2|T100:2, T96:3|T100:3, T97:0|T101:0, T97:1|T101:1, T97:2|T101:2, T97:3|T101:3, T98:0|T102:0, T98:1|T102:1, T98:2|T102:2, T98:3|T102:3, T99:0|T103:0, T99:1|T103:1, T99:2|T103:2, T99:3|T103:3]
[ T104:0|T108:0, T104:1|T108:1, T104:2|T108:2, T104:3|T108:3, T105:0|T109:0, T105:1|T109:1, T105:2|T109:2, T105:3|T109:3, T106:0|T110:0, T106:1|T110:1, T106:2|T110:2, T106:3|T110:3, T107:0|T111:0, T107:1|T111:1, T107:2|T111:2, T107:3|T111:3]
[ T112:0|T116:0, T112:1|T116:1, T112:2|T116:2, T112:3|T116:3, T113:0|T117:0, T113:1|T117:1, T113:2|T117:2, T113:3|T117:3, T114:0|T118:0, T114:1|T118:1, T114:2|T118:2, T114:3|T118:3, T115:0|T119:0, T115:1|T119:1, T115:2|T119:2, T115:3|T119:3]
[ T120:0|T124:0, T120:1|T124:1, T120:2|T124:2, T120:3|T124:3, T121:0|T125:0, T121:1|T125:1, T121:2|T125:2, T121:3|T125:3, T122:0|T126:0, T122:1|T126:1, T122:2|T126:2, T122:3|T126:3, T123:0|T127:0, T123:1|T127:1, T123:2|T127:2, T123:3|T127:3]]
- shared layout
1
2
3
4
5
6
$ triton-tensor-layout -l "#triton_gpu.shared<{vec = 2, perPhase = 1, maxPhase = 4, order = [1,0], hasLeadingOffset = false}>" -t "tensor<4x8xf16>"
Print layout attribute: #triton_gpu.shared<{vec = 2, perPhase = 1, maxPhase = 4, order = [1, 0], hasLeadingOffset = false}>
[[(0:0),(0:1),(0:2),(0:3),(0:4),(0:5),(0:6),(0:7)]
[ (1:2),(1:3),(1:0),(1:1),(1:6),(1:7),(1:4),(1:5)]
[ (2:4),(2:5),(2:6),(2:7),(2:0),(2:1),(2:2),(2:3)]
[ (3:6),(3:7),(3:4),(3:5),(3:2),(3:3),(3:0),(3:1)]]
默认打印是每个 thread 对应的 tensor 上的元素,默认是从 tensor 角度出发来打印每个 thread 对应的 tensor 上的元素; 也可以增加 -use-hw-view 以获取 warps, threads 角度获得更多信息。
用法细节请自行阅读:bin/triton-tensor-layout.cpp 以及 lib/Dialect/TritonGPU/IR/Dialect.cpp。
ttir-2-ttgir
设计上:
1.通过 typeConverter 保存 numWarps, threadsPerWarp, numCTAs, target 这些 compile hint,并在 conversion pattern 中使用以指导下降。默认 threadsPerWarp = 32, numCTAs = 1。
2.将 conversion pattern 组织成 arith, math, triton, scf, cf 类,来覆盖当可能的 ir input,再使用 applyPartialConversion 来apply pattern。
applyFullConversion/applyPartialConversion 都尝用于 ConversionPatternDriver,在conversion中往往需要多次命中 pattern 才能 legal。 所以 Conversion Pattern 搭配
adaptor一起使用,来获得 Conversion 过程中正确的 operand 信息。相比
FullConversion,PartialConversion约束更宽松,如果结果是合法(以ConversionTarget参数来判断)则保留。如果有未转换的illegal操作,并不会转换失败,将混合存在。
3.最后在 Module 上将 numWarps, threadsPerWarp, numCTAs, target 这些 compile hint 设置为 Attribute 继续传递下去。
本文的重点也就在上述定义的 ConversionPattern。
Conversion
Conversion 主要包含 TypeConverter 和 ConversionTarget,前者定义对类型的修改(主要是为 RankedTensorType 挂上 BlockLayout),后者定义在conversion中的legal target。
TritonGPUConversionTarget
使用下面的方法定义当前 Conversion Target。当前并没有直接把 triton::TritonDialect 设为非法, 特别是 tt.dot 当 A 和 B operand 上带有 DotOperandEncodingAttr 时是合法的,说明一定情况下 ttir 和 ttgir 会共存。
- Dialect
- addLegalDialect
- addIllegalDialect
- addDynamicallyLegalDialect
- Operation
- addLegalOp
- addIllegalOp
- addDynamicallyLegalOp
- markUnknownOpDynamicallyLegal
TritonGPUTypeConverter
TypeConverter 需要定义以下的内容:
addConversion:定义通用的类型转换规则,当调用convertType方法时,会依次检查addConversion中注册的规则。- 但其实会自动遍历 ir 将符合的 type 都尝试转换。
addTargetMaterialization:sourceType→targetType- 例如,op2 以 op1 作为 operand,当 op1 和 op2 的 resType 被转换后, op2 期望其 operandType 和 op1 给出的并不符合,所以需要使用addTargetMaterialization将 op1 的 resType转换成 op2 期望的 operandTyp
- 一般会先插入
builtin.unrealized_conversion_cast来保持 ir 正确,然后使用addTargetMaterialization中定义的方法替换掉unrealized_conversion_cast。
addSourceMaterialization:targetType→sourceTypeaddArgumentMaterialization
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class MyTypeConvert : public TypeConverter {
public:
MyTypeConvert() {
addConversion([](Type type)) -> Type {
if (isSomeType(type))
return ...;
return type;
});
}
// 一般来说,默认是 builtin.unrealized_conversion_cast
auto addUnrealizedCast = [](OpBuilder &builder, Type type, ValueRange inputs,
Location loc) {
auto cast = builder.create<UnrealizedConversionCastOp>(loc, type, inputs);
return std::optional<Value>(cast.getResult(0));
};
addTargetMaterialization(addUnrealizedCast);
addSourceMaterialization(addUnrealizedCast);
addArgumentMaterialization(addUnrealizedCast);
}
1.TritonGPUTypeConverter 的 Type Conversion Pattern是:
- 当 Type 是 RankedTensorType 时,挂上 BlockedEncodingAttr(即上文的Block Layout)。
- 当 Type 是 PointerType,且
PointeeType是 RankedTensorTyp,给其PointeeType挂上 BlockedEncodingAttr。
注意:当 operand type 符合上面的条件的时候其实被认为是 illegal 的,只有挂上 Block Layout 后才是 leagal 的。
当传入 target=cuda:80,其他采用默认时:
| input type | output (after convert) |
|---|---|
| tensor<64x2x32xf16> | tensor<64x2x32xf16, #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 1, 32], warpsPerCTA = [2, 2, 1], order = [2, 1, 0]}» |
| tensor<32x64x2xf16> | tensor<32x64x2xf16, #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 16, 2], warpsPerCTA = [1, 4, 1], order = [2, 1, 0]}» |
| tensor<64x2x64x2xf32> | tensor<64x2x64x2xf32, #triton_gpu.blocked<{sizePerThread = [1, 1, 1, 1], threadsPerWarp = [1, 1, 16, 2], warpsPerCTA = [1, 1, 4, 1], order = [3, 2, 1, 0]}» |
| !tt.ptr<tensor<128x32xf16> | !tt.ptr<tensor<128x32xf16, #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}»> |
挂 BlockedEncodingAttr 使用 getDefaultBlockedEncoding 方法。 计算的规则为从最内维开始分配当前剩下的 threads 和 warps,尽量分配 thread = shapePerCTA[i] / sizePerThread[i] ,保证低维数据能在一次被搬运完,访存的连续性更好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// include/triton/Dialect/TritonGPU/IR/TritonGPUAttrDefs.td
// sizePerThread(rank, 1)
// order(rank - 1, rank - 2, .. , 0)
// 若无传入,则使用默认参数:numWarps = 4, threadsPerWarp = 32, numCTAs = 1
// 默认 CTAsPerCGA = CTASplitNum = [1...1]
unsigned rank = sizePerThread.size();
SmallVector<unsigned, 4> threadsPerWarp(rank);
SmallVector<unsigned, 4> warpsPerCTA(rank);
// CTASplitNum = [1...1] -> shapePerCTA = shape
SmallVector<int64_t> shapePerCTA = getShapePerCTA(CTALayout.getCTASplitNum(), shape);
unsigned remainingLanes = numThreadsPerWarp; // threadsPerWarp = 32
unsigned remainingThreads = numWarps * numThreadsPerWarp; // 128
unsigned remainingWarps = numWarps; // 4
unsigned prevLanes = 1;
unsigned prevWarps = 1;
// starting from the contiguous dimension
for (unsigned d = 0; d < rank - 1; ++d) {
unsigned i = order[d]; // order是从大到小的序列,所以i会从大到小遍历
unsigned threadsPerCTA = std::clamp<unsigned>(remainingThreads, 1, std::max<unsigned>(1, shapePerCTA[i] / sizePerThread[i]));
threadsPerWarp[i] = std::clamp<unsigned>(threadsPerCTA, 1, remainingLanes);
warpsPerCTA[i] = std::clamp<unsigned>(threadsPerCTA / threadsPerWarp[i], 1, remainingWarps);
remainingWarps /= warpsPerCTA[i];
remainingLanes /= threadsPerWarp[i];
remainingThreads /= threadsPerCTA;
prevLanes *= threadsPerWarp[i];
prevWarps *= warpsPerCTA[i];
}
// Expand the last dimension to fill the remaining lanes and warps
threadsPerWarp[order[rank - 1]] = numThreadsPerWarp / prevLanes;
warpsPerCTA[order[rank - 1]] = numWarps / prevWarps;
2.TritonGPUTypeConverter 的 addTargetMaterialization:
插入 triton_gpu.convert_layout 转换 type 的 layout encoding。 例如对下面的ir进行转换,op1 按照顺序先被转换,op2 期望 op1 给出的 layout 是 #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [1, 0]}>, 这与 op1 的 resType 不相同,所以就会插入 triton_gpu.convert_layout。
1
2
3
4
5
6
7
8
9
10
%op1 = tt.expand_dims %xx {axis = 1 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>}>> -> tensor<128x1xi32, #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>>
%op2 = tt.broadcast %op1 : tensor<128x1xi32> -> tensor<128x32xi32>
->
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [1, 0]}>
%op1 = tt.expand_dims %xx {axis = 1 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>> -> tensor<128x1xi32, #blocked1>
%cast = triton_gpu.convert_layout %op1 : tensor<128x1xi32, #blocked1> -> tensor<128x1xi32, #blocked2>
%op2 = tt.broadcast %cast : tensor<128x1xi32, #blocked2> -> tensor<128x32xi32, #blocked2>
Arith & Math
基本的 op 都走 GenericOpPattern,即只修改对应的 operand type:
1
2
3
4
5
if (failed(this->getTypeConverter()->convertTypes(op->getResultTypes(),
retTypes)))
return failure();
rewriter.replaceOpWithNewOp<Op>(op, retTypes, adaptor.getOperands(),
op->getAttrs());
convertTypes 最终是根据输入的 Type 选择上文 TritonGPUTypeConverter 定义的 addConversion 函数。
- 当 Type 是 RankedTensorType 时,挂上 BlockedEncodingAttr(即上文的Block Layout)。
- 当 Type 是 PointerType,且
PointeeType是 RankedTensorTyp,给其PointeeType挂上 BlockedEncodingAttr。 - 其他则不改变
Triton
许多 op 也是走 GenericOpPattern 下降,这些 op 就不再介绍,后序这些 op 直接从 ttir 下降到 llvm (lib/Conversion/TritonGPUToLLVM/ElementwiseOpToLLVM.cpp)。
注意在构造例测试时 blockArg 的 Type 不能是 RankedTensorType 或 !tt.ptr<tensor<xxx>>,即不能是 addConversion 中注册的会发生改变的 Type,不然会直接 coredump! 因为 TritonGPUTypeConverter 中 addArgumentMaterialization 是直接不处理的。 (但其实 Triton-Lang 下降得到的 ir 的 blockarg 只可能是标量或者 !tt.ptr,所以生成的 ir 并不会出现意外)。
1
2
3
4
5
6
7
addArgumentMaterialization([&](OpBuilder &builder,
RankedTensorType tensorType, ValueRange inputs,
Location loc) -> std::optional<Value> {
llvm_unreachable("Argument rematerialization should not happen in Triton "
"-> TritonGPU conversion");
return std::nullopt;
});
tt.broadcast
以 src 的 type 上的 layout encoding 来创建新的 resultType。
1
2
3
4
5
6
%a = tt.broadcast %b : tensor<128x1xi32> -> tensor<128x32xi32>
->
#triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>
%a = tt.broadcast %b : tensor<128x1xi32, #blocked> -> tensor<128x32xi32, #blocked>
其实原始的 tensor<128x32xi32>(resType) convert 后的得到的 layout 应该是 #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [0, 1]}>
tt.cat
tt.cat 在最高维进行 concatenate。 将 resTy 加上 BlockLayout 后,然后根据 lhs 和 rhs 的信息获得新的 sizePerThread 来重新创建 resType layout。
1
2
newRetTotalElemsPerThread = next_power_of_2(lhs.total_elems_per_thread + rhs.total_elems_per_thread)
newRetSizePerThread[retOrder[0]] *= newRetTotalElemsPerThread / retTotalElemsPerThread;
下面是一个 tt.cat 下降的例子:
- 两个 operand(lhs, rhs) 的 type 完全相同(td中标明了
SameTypeOperands),所以它们的 BlockLayout 一定也相同。 - tensor<32x1x1xf16> 本来会被assign的 Block layout 是 sizePerThread = [1, 1, 1],然后根据上面的计算公式得到新的 sizePerThread = [1, 1, 2]
1
2
3
4
5
6
7
8
9
%cst = arith.constant dense<1.000000e+00> : tensor<16x1x1xf16>
%0 = tt.cat %cst, %cst : tensor<16x1x1xf16> -> tensor<32x1x1xf16>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [32, 1, 1], warpsPerCTA = [4, 1, 1], order = [2, 1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1, 2], threadsPerWarp = [32, 1, 1], warpsPerCTA = [4, 1, 1], order = [2, 1, 0]}>
%cst = arith.constant dense<1.000000e+00> : tensor<16x1x1xf16, #blocked>
%0 = tt.cat %cst, %cst : tensor<16x1x1xf16, #blocked> -> tensor<32x1x1xf16, #blocked1>
其实这里有一个疑惑点,tt.cat 是在最高维进行拼接,但是新计算好的应该放在 newRetSizePerThread[0] 更合理, 而newRetSizePerThread[retOrder[0]] 其实就是 newRetSizePerThread[rank - 1] ,这是更新了最内维。
或许解释为是先给 order 靠前的区域?
tt.join
tt.join 和 tt.cat 类似,都是拼接tensor,但 join 会(在最内维)增加维度,而 cat 只(在最外维)改变DimSize不会增加维度。
下面是一个 tt.join 下降的例子:
<16x32x2xf16> 的默认 block layout 应该是 #blocked1,但新生成的 tt.join 的 resTy 的 block layout 居然是 #blocked2, sizePerThread 在最内维度是 2,反而像 tt.cat 的期望变化了,但代码中并没有显示表现这部分。。
1
2
3
4
5
6
7
8
9
10
11
12
%cst = arith.constant dense<1.000000e+00> : tensor<16x32xf16>
%cst1 = arith.constant dense<1.000000e+00> : tensor<16x32x2xf16>
%0 = tt.join %cst, %cst : tensor<16x32xf16> -> tensor<16x32x2xf16>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 16, 2], warpsPerCTA = [2, 2, 1], order = [2, 1, 0]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1, 2], threadsPerWarp = [1, 32, 1], warpsPerCTA = [4, 1, 1], order = [2, 1, 0]}>
%cst = arith.constant dense<1.000000e+00> : tensor<16x32xf16, #blocked>
%cst_0 = arith.constant dense<1.000000e+00> : tensor<16x32x2xf16, #blocked1>
%0 = tt.join %cst, %cst : tensor<16x32xf16, #blocked> -> tensor<16x32x2xf16, #blocked2>
tt.split
tt.split 用于将一个 tensor 沿最内维 均分为两部分,要求最内维 DimSize = 2。
下面是一个 tt.split 下降的例子:
split 的 resTy(tensor<16x32xf16>) 会的 block layout 是 #block2,由此其实可以反推出其 srcTy 的 sizePerThread 应该为 [1, 1, 2] 以满足在最内维进行 split, 但%cst 给出的 block layout 并不符合,所以按照前文的讲解,会调用 addTargetMaterialization 来创建 triton_gpu.convert_layout 来将当前 layout 转换为期望的 layout。
1
2
3
4
5
6
7
8
9
10
11
%cst = arith.constant dense<1.000000e+00> : tensor<16x32x2xf16>
%0, %1 = tt.split %cst : tensor<16x32x2xf16> -> tensor<16x32xf16>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 16, 2], warpsPerCTA = [2, 2, 1], order = [2, 1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1, 2], threadsPerWarp = [1, 32, 1], warpsPerCTA = [4, 1, 1], order = [2, 1, 0]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
%cst = arith.constant dense<1.000000e+00> : tensor<16x32x2xf16, #blocked>
%0 = triton_gpu.convert_layout %cst : tensor<16x32x2xf16, #blocked> -> tensor<16x32x2xf16, #blocked1>
%outLHS, %outRHS = tt.split %0 : tensor<16x32x2xf16, #blocked1> -> tensor<16x32xf16, #blocked2>
tt.expand_dims
tt.expand_dims 用来扩展维度,有一个输入来指定需要扩展的维度,一次仅扩展1维,扩展后的维度dimSize为1。很像 tensor.expand_shape。
下面是一个 tt.expand_dims 下降的例子:
- resTy layout 的
sizePerThread, threadsPerWarp, warpsPerCTA是依据 srcTy layout 在对应的dim(getAxis()) 上插入 1 创建得到的 - resTy layout 的 order 是从小到大的数组
std::iota(retOrder.begin(), retOrder.end(), 0)- 这一点很疑惑,为啥不是把扩展的这维作为新 order 中最后一个?
- srcTy block layout 会先转为 resTy block layout 相关的 slice layout,表示这两者之间的关系
- 如下面的 #triton_gpu.slice<{dim = 1, parent = #blocked2}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
%1 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32>
%2 = tt.expand_dims %1 {axis = 1 : i32} : tensor<128xi32> -> tensor<128x1xi32>
%3 = tt.expand_dims %2 {axis = 0 : i32} : tensor<128x1xi32> -> tensor<1x128x1xi32>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>
#blocked3 = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 32, 1], warpsPerCTA = [1, 4, 1], order = [0, 1, 2]}>
%0 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #blocked1>
%1 = triton_gpu.convert_layout %0 : tensor<128xi32, #blocked1> -> tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked2}>>
%2 = tt.expand_dims %1 {axis = 1 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked2}>> -> tensor<128x1xi32, #blocked2>
%3 = triton_gpu.convert_layout %2 : tensor<128x1xi32, #blocked2> -> tensor<128x1xi32, #blocked>
%4 = triton_gpu.convert_layout %3 : tensor<128x1xi32, #blocked> -> tensor<128x1xi32, #triton_gpu.slice<{dim = 0, parent = #blocked3}>>
%5 = tt.expand_dims %4 {axis = 0 : i32} : tensor<128x1xi32, #triton_gpu.slice<{dim = 0, parent = #blocked3}>> -> tensor<1x128x1xi32, #blocked3>
tt.trans
tt.trans 用来对 tensor 进行转置,其 op.getOrder() 能直接获得对 srcTy shape 和 resTy shape 映射的关系。
下面是一个 tt.trans 下降的例子:
看 TritonTransPattern 看不出啥。。 但是看例子可以发现 resTy 的 layout 和 srcTy 的 layout 是符合 trans 的 getOrder 属性的。就像直接对 block layout 中每个属性应用了 applyPermutation。
applyPermutation 函数来自 mlir/include/mlir/Dialect/Utils/IndexingUtils.h
1
2
3
4
5
6
7
8
9
%cst = arith.constant dense<1.000000e+00> : tensor<64x2x16xf16>
%0 = tt.trans %cst {order=array<i32: 1, 2, 0>} : tensor<64x2x16xf16> -> tensor<2x16x64xf16>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [1, 2, 16], warpsPerCTA = [4, 1, 1], order = [2, 1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1, 1], threadsPerWarp = [2, 16, 1], warpsPerCTA = [1, 1, 4], order = [1, 0, 2]}>
%cst = arith.constant dense<1.000000e+00> : tensor<64x2x16xf16, #blocked>
%0 = tt.trans %cst {order = array<i32: 1, 2, 0>} : tensor<64x2x16xf16, #blocked> -> tensor<2x16x64xf16, #blocked1>
tt.dot
在 conversion 中,
首先,会根据当前的 operand shape 来强制指定最后 resTy layout 最后两维 retSizePerThread 信息。
这应该是之后 dot 下降成指令有 operand type 需求。笔者暂时没找到对应的指令约束。
1
2
3
4
5
6
7
8
9
auto numElements = product<int64_t>(origShape);
if (numElements / (numWarps * threadsPerWarp) >= 4) {
retSizePerThread[rank - 1] = 2;
retSizePerThread[rank - 2] = 2;
}
if (numElements / (numWarps * threadsPerWarp) >= 16) {
retSizePerThread[rank - 1] = 4;
retSizePerThread[rank - 2] = 4;
}
然后,若a, b不是特定的编码类型(DotOperandEncodingAttr),则生成 triton_gpu.convert_layout 将 layout 转换为 DotOperand Layout, 该 layout 表示 dotOp 的输入的 layout。主要包含 opIdx 和 parent 两个信息,
- opIdx :用来标识 dotOp 的操作数
- opIdx=0 表示 DotOp 的 $a
- opIdx=1 表示 DotOp 的 $b
- parent:决定了 DotOperand 的布局方式
- MMA Layout(如果 DotOp lower 到 MMA 指令)
- Blocked Layout(如果 DotOp lower 到 FMA 指令)
下面是一个 tt.dot 下降的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
%a = arith.constant dense<1.00e+00> : tensor<128x32xf16>
%b = arith.constant dense<2.00e+00> : tensor<32x128xf16>
%c = arith.constant dense<3.00e+00> : tensor<128x128xf32>
%0 = tt.dot %a, %b, %c : tensor<128x32xf16> * tensor<32x128xf16> -> tensor<128x128xf32>
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [1, 4], order = [1, 0]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [4, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
%cst = arith.constant dense<1.000000e+00> : tensor<128x32xf16, #blocked>
%cst_0 = arith.constant dense<2.000000e+00> : tensor<32x128xf16, #blocked1>
%cst_1 = arith.constant dense<3.000000e+00> : tensor<128x128xf32, #blocked1>
%0 = triton_gpu.convert_layout %cst : tensor<128x32xf16, #blocked> -> tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #blocked2}>>
%1 = triton_gpu.convert_layout %cst_0 : tensor<32x128xf16, #blocked1> -> tensor<32x128xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #blocked2}>>
%2 = triton_gpu.convert_layout %cst_1 : tensor<128x128xf32, #blocked1> -> tensor<128x128xf32, #blocked2>
%3 = tt.dot %0, %1, %2 : tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #blocked2}>> * tensor<32x128xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #blocked2}>> -> tensor<128x128xf32, #blocked2>
SCF & CF
这些都是控制流相关的 op,需要额外处理 region 内的 op 以及 region 上的 operandType 和 resType。
基本的流程都差不多是:
- clone op without region + inline region before
- newOp->setOperands(adaptor.getOperands());
- get new resTy and set
- replace op
以 scf.for 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
%a = arith.constant dense<1.00e+00> : tensor<128x32xf16>
%b = arith.constant dense<2.00e+00> : tensor<32x128xf16>
%c = arith.constant dense<3.00e+00> : tensor<128x128xf32>
%1 = scf.for %arg = %c0 to %c32 step %c1 iter_args(%arg1 = %c) -> (tensor<128x128xf32>) {
%dot = tt.dot %a, %b, %arg1 : tensor<128x32xf16> * tensor<32x128xf16> -> tensor<128x128xf32>
scf.yield %dot : tensor<128x128xf32>
} {tt.num_stages = 3 : i32}
->
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [1, 4], order = [1, 0]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [4, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
%cst = arith.constant dense<1.000000e+00> : tensor<128x32xf16, #blocked>
%cst_0 = arith.constant dense<2.000000e+00> : tensor<32x128xf16, #blocked1>
%cst_1 = arith.constant dense<3.000000e+00> : tensor<128x128xf32, #blocked1>
%0 = scf.for %arg0 = %c0 to %c32 step %c1 iter_args(%arg1 = %cst_1) -> (tensor<128x128xf32, #blocked1>) {
%1 = triton_gpu.convert_layout %cst : tensor<128x32xf16, #blocked> -> tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #blocked2}>>
%2 = triton_gpu.convert_layout %cst_0 : tensor<32x128xf16, #blocked1> -> tensor<32x128xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #blocked2}>>
%3 = triton_gpu.convert_layout %arg1 : tensor<128x128xf32, #blocked1> -> tensor<128x128xf32, #blocked2>
%4 = tt.dot %1, %2, %3 : tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #blocked2}>> * tensor<32x128xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #blocked2}>> -> tensor<128x128xf32, #blocked2>
%5 = triton_gpu.convert_layout %4 : tensor<128x128xf32, #blocked2> -> tensor<128x128xf32, #blocked1>
scf.yield %5 : tensor<128x128xf32, #blocked1>
} {tt.num_stages = 3 : i32}
transforms in ttgir
集中在 lib/Dialect/TritonGPU/Transforms/ 中,内容很多,等之后有时间慢慢整理吧。TBC..