
background
triton 是 使用 Python 来写 cuda + block内的优化交给 compiler
numba
对比和triton类似的解决方案 numba
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
BLOCK = 512
# This is a GPU kernel in Numba.
@jit
def add(X, Y, Z, N):
# In Numba/CUDA, each kernel
# instance itself uses an SIMT execution
# threadId 很重要
tid = threadIdx.x
bid = blockIdx.x
# scalar index
idx = bid * BLOCK + tid
if id < N:
# There is no pointer in Numba.
# Z,X,Y are dense tensors
Z[idx] = X[idx] + Y[idx]
...
grid = (ceil_div(N, BLOCK),)
block = (BLOCK,)
add[grid, block](x, y, z, x.shape[0])
numba特点:
- 显式控制 launch 行为(grid, block),和 cuda 几乎一致
- 编程范式
- 输入为 tensor
- SIMT 行为,控制每个 thread 的行为
- 和 cuda 强耦合,支持多 backend 困难
triton
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
BLOCK = 512
# This is a GPU kernel in Triton.
@jit
def add(X, Y, Z, N):
# 操作和 threadId 无关
pid = program_id(0)
# block of indices
idx = pid * BLOCK + arange(BLOCK)
mask = idx < N
# Triton 使用指针
x = load(X + idx, mask=mask)
y = load(Y + idx, mask=mask)
store(Z + idx, x + y, mask=mask)
...
grid = (ceil_div(N, BLOCK),)
# no thread-block
add[grid](x, y, z, x.shape[0])
triton 特点:
- 只定义 grid 信息, thread block内的行为由算法定义
- CTA 内的 wrap 数量可通过 tuning config 配置
- 算法范式
- 输入数据一般为标量和 tensor指针
- SPMD
- 屏蔽内存层级管理
cuda vs triton
cuda和triton编程模式对比
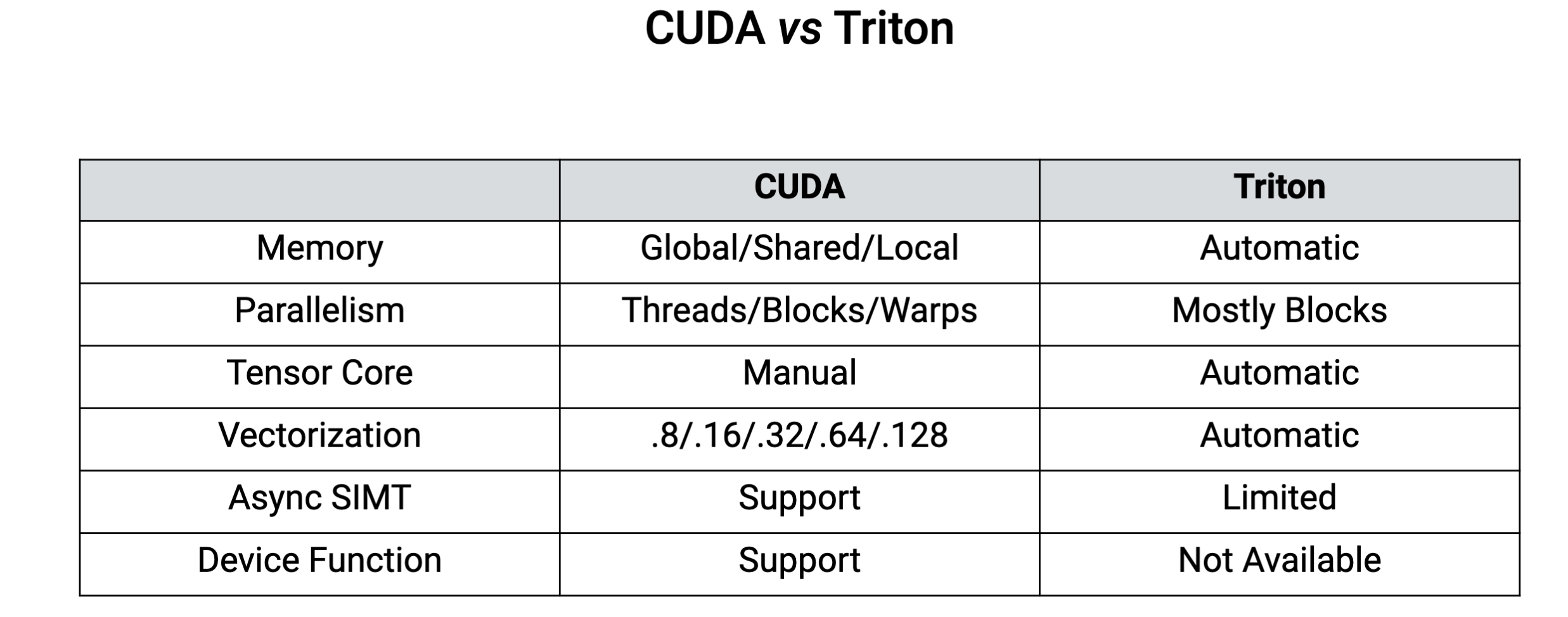
相比 cuda, triton 其实是 性能和效率的 trade-off。很多 cuda 上人为的操作行为都是交给 compiler 来自动完成,很适合对硬件了解较少的同学来实现新的模型算法。
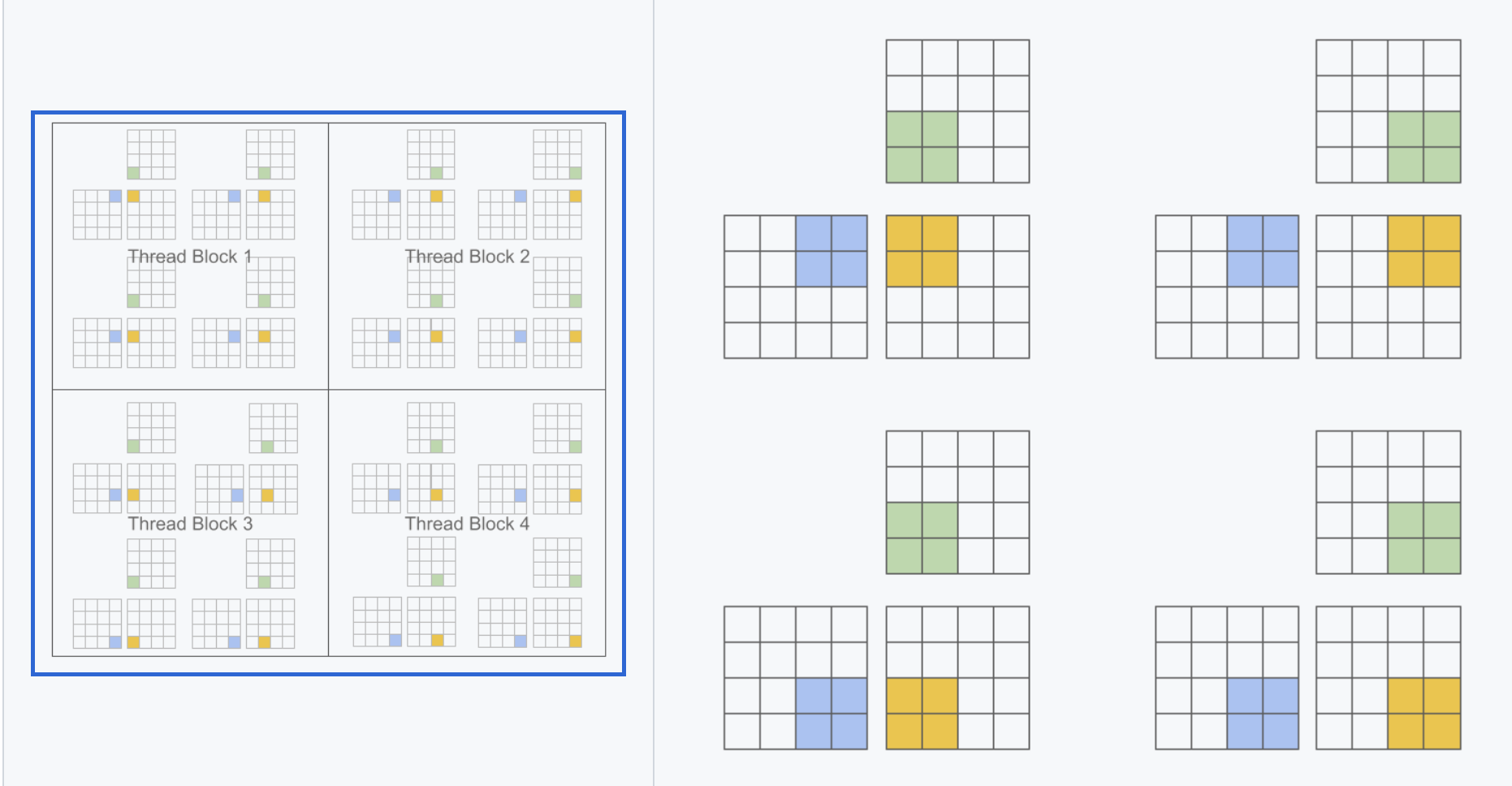
比CUDA的SIMT编程范式,由多个thread并行处理,triton更接近SIMD编程范式,一次处理一片数据(基于block算法的编程范式)
直接对线程块进行编程,每一个操作都是应用在块上,不再控制单个的线程,省去线程之间的同步等操作。将基于block的算法映射到SIMT架构上的行为由compiler来负责。
推荐repo
OpenAI Triton 是什么?这个问题很多大佬都已经回答过了,阅读完以下 blog 相信大家会有个基础的理解
- 杨军老师的 谈谈对OpenAI Triton的一些理解,帮助大家建立一个宏观印象
- OpenAI/Triton MLIR 迁移工作简介,对 triton 的架构有个宏观介绍。
- 董鑫大佬的 如何入门 OpenAI Triton 编程?,帮助了解更多关于语法上的信息
- BobHuang大佬的 浅析 Triton 执行流程,帮助初学者大致明白一段 python 程序如何进入 triton pipeline,然后跑起来。
- 理解triton语法的repo:triton-puzzles
- 很多用triton实现的kernel的repo:lightllm
triton 开发流程
op define + launch function + call
代码来源: tutorials/01-vector-add.py
- op define
使用 @triton.jit 修饰的 kernel 算法
1
2
3
4
5
6
7
8
9
@triton.jit
def add_kernel(
x_ptr, # *Pointer* to first input vector.
y_ptr, # *Pointer* to second input vector.
output_ptr, # *Pointer* to output vector.
n_elements, # Size of the vector.
BLOCK_SIZE: tl.constexpr, # Number of elements each program should process.
# NOTE: `constexpr` so it can be used as a shape value.
):
kernel的参数类型一般是ptr/正整数/constexpr类型,如上。
可见,一个数若要作为blockarg传入kernel,可以直接以正整数形式传入,也可以标记tl.constexpr,区别在于: tl.constexpr 要求编译期已知,方便进行codegen,故若在 tune config 中给出了该变量的 search space,那么会针对这些 search space 分别编译一次,保留性能最优的那此编译结果存于 cache。
- launch function
1
2
3
4
5
6
7
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
- call
1
2
3
4
5
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
output_triton = add(x, y)
triton 组成
triton 的组成:
- language:前端的triton-lang语法
- compiler:kernel编译的行为,会根据后端调用对应的pipeline,把triton-lang下降到硬件汇编
- runtime:cache,autotuner, jit 等组件
- backends: 编译完后,在执行时掉用的是真实后端,例如 nvgpu,这里主要包含 compiler 时的 pipeline 组织, launch 函数(使用模版加真实kernel参数生成真实的launch函数)等
languague
作为 triton 项目的 fontend,包含每个原语的构造行为(例如op的某些类型会偷偷转为默认的f32来计算)。
官方提供了原语的用法手册:https://triton-lang.org/main/index.html
tl规定了ir必须表达为static的,不允许 mlir 中 dynamic shape 的表达。
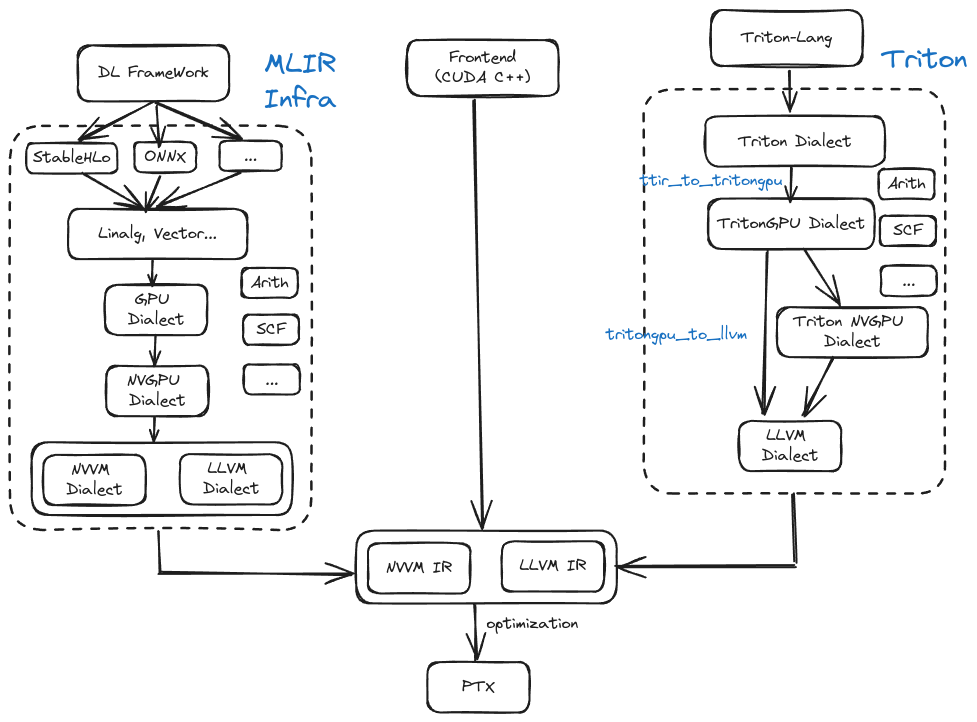
compiler
以 nvgpu 为例,triton-lang 的下降流程:
triton-lang -> triton dialect -> triton gpu dialect -> triton nvgpu dialect -> llvm ir + nvvm ir -> ptx -> cubin
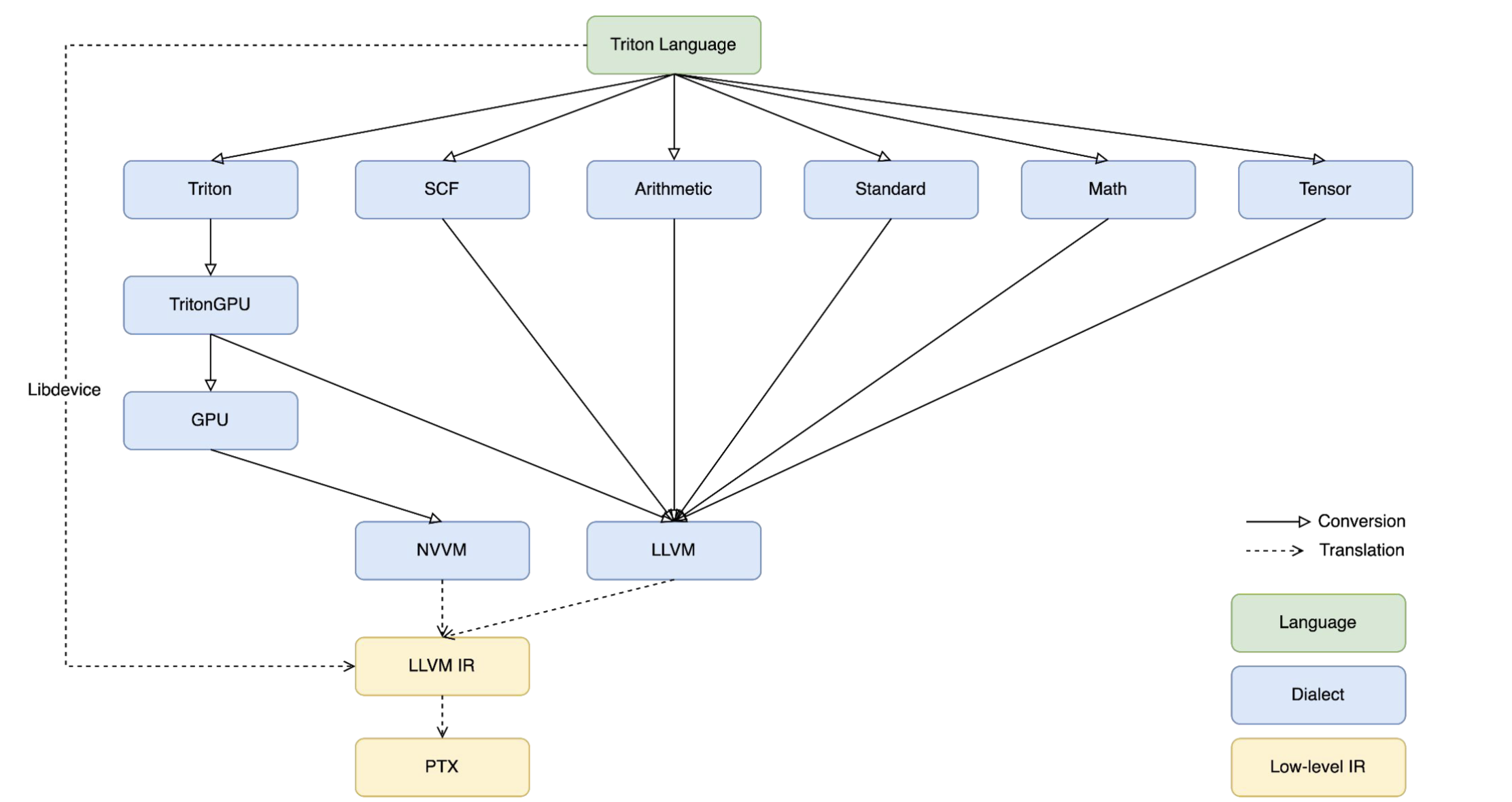
triton-lang(python) -> ast -> ttir:遍历整个语法树,通过code_generator相关代码,定义visit_Assign等函数,通过mlir builder生成对应的mlir。
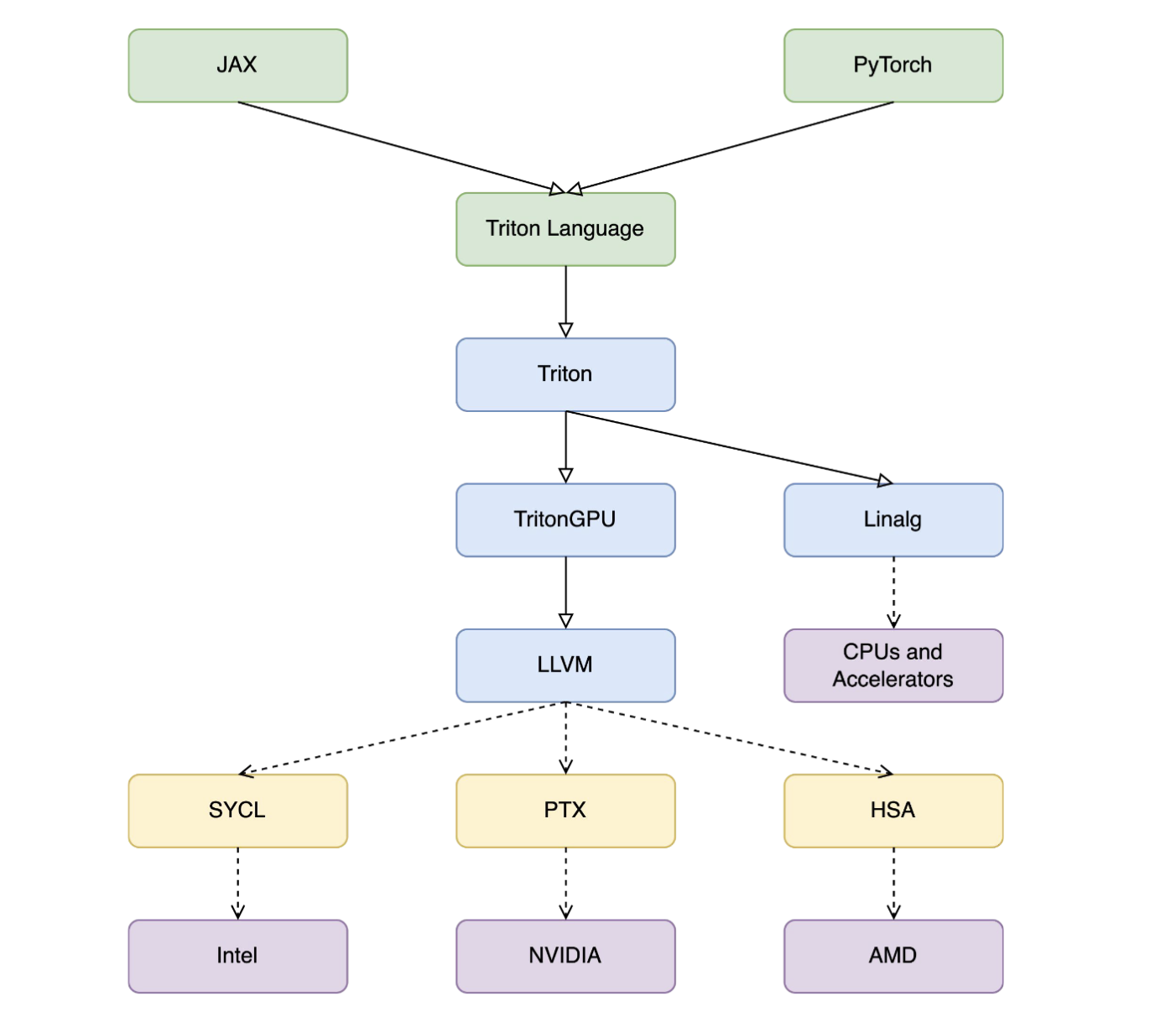
compiler支持多后端的方向:通过Linalg dialect
runtime
jit
@triton.jit装饰器 表示下面这段代码是一个 triton kernel
编译流程中,首先会将 jit 修饰的 kernel 给打包成一个 JITFunction,见 runtime/jit.py。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def jit(
fn: Optional[T] = None,
*,
version=None,
repr: Optional[Callable] = None,
launch_metadata: Optional[Callable] = None,
do_not_specialize: Optional[Iterable[int]] = None,
do_not_specialize_on_alignment: Optional[Iterable[int]] = None,
debug: Optional[bool] = None,
noinline: Optional[bool] = None,
) -> Union[JITFunction[T], Callable[[T], JITFunction[T]]]:
def decorator(fn: T) -> JITFunction[T]:
assert callable(fn)
if os.getenv("TRITON_INTERPRET", "0") == "1":
from .interpreter import InterpretedFunction
return InterpretedFunction(fn) # 使用Interpreter执行,完全不会走到任何编译流程,使用numpy&torch api 封装
else:
return JITFunction(
fn,
version=version,
do_not_specialize=do_not_specialize,
debug=debug,
noinline=noinline,
repr=repr,
launch_metadata=launch_metadata,
) # 编译
@triton.jit的do_not_specialize参数,来阻止 triton 生成过多的 kernel。triton jit 会以每一个非指针参数为准,去生成一个kernel,比如某一个参数运行时取值可能为1或0,那么 triton 就会为它们各生成一个。
JITFunction 对象继承自 KernelInterface,并封装了一些调用语法糖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# python/triton/runtime/jit.py
class KernelInterface(Generic[T]):
run: T
def __getitem__(self, grid) -> T:
"""
A JIT function is launched with: fn[grid](*args, **kwargs).
Hence JITFunction.__getitem__ returns a callable proxy that
memorizes the grid.
"""
return lambda *args, **kwargs: self.run(grid=grid, warmup=False, *args, **kwargs)
class JITFunction(KernelInterface[T]):
cache_hook = None
...
def run(self, *args, grid, warmup, **kwargs):
...
key = ''.join(sig_and_spec) + str((constexpr_vals, excess_kwargs))
kernel = self.cache[device].get(key, None)
if kernel is None:
# Kernel is not cached; we have to compile.
...
src = self.ASTSource(self, signature, constants, configs[0]) # ast 转 ttir
kernel = self.compile( # ttir 一路下降到 cubin
src,
target=target,
options=options.__dict__,
)
...
if not warmup:
...
kernel.run(...) # 调用 drive api执行cubin
lambda *args, **kwargs: self.run(grid=grid, warmup=False, *args, **kwargs):将grid参数封装传入进去, 除了定义的kernel参数外,还会额外传入num_wraps, stages, stream等参数。
1
2
3
4
5
# 人为写出的kernel调用
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
# 真实的kernel调用
add_kernel(x.data_ptr, y.data_ptr, output, n_elements, BLOCK_SIZE=1024, grid, num_warps=4, num_stages=3, extern_libs=None, stream=None, warmup=False)
autotune
@autotune :由 @triton.jit装饰的kernel可以调用 @autotune detector触发自动调优
使用上需要提供一个configs(包含在kernel中定义的 tl.constexpr)列表,autotune会多次运行kernel函数来评估configs中的所有配置。(配置是人为给出的,所以空间不大,依赖人为经验)
- key:参数列表,当key中的参数改变时,需要重新评估tuning
- prune_configs_by:用户可以传入函数来帮助减枝(例如基于性能模型的函数),加快收敛
- reset_to_zero:输入参数名列表,这些参数的值在评估任何配置之前将被重置为零。
- restore_value:输入参数名列表,这些参数的值在评估任何配置之前将被重置为初始值。(某些kernel是inplace的)
- warmup:每个config的warmup时间,默认25ms
- rep:每个config的重复时间,默认100ns
1
2
3
4
5
6
7
8
9
10
11
12
13
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=3, num_warps=8),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
triton.Config({'BLOCK_SIZE_M': 32, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
],
key=['M', 'N', 'K'],
)
(1)当前要求所有BLOCK_SIZE设置的值都得是2次幂,因为在gpu上数据为2次冪的规模时性能更好。
1
2
n_rows, n_cols = x.shape
BLOCK_SIZE = triton.next_power_of_2(n_cols)
(2)暴力细粒度tune时间太常,可以通过 prune_configs_by 减枝
1
2
3
4
5
@triton.autotune(
configs=cfggen_reduce_op(),
key=["M"],
prune_configs_by={'early_config_prune': prune_reduce_config}
)
设置这个 prune_func 需要根据经验以及硬件。
1
2
3
4
5
6
7
8
9
10
11
12
def prune_reduce_config(configs, named_args, **kwargs):
M = named_args["M"]
pruned_configs = []
for config in configs:
BLOCK_SIZE = config.kwargs["BLOCK_SIZE"]
num_stages = config.num_stages
num_block = M // BLOCK_SIZE
...
if (len(pruned_configs) == 0):
pruned_configs.append(triton.Config({"BLOCK_SIZE": next_power_of_two(M)}, num_warps=4, num_stages=1))
return pruned_configs
(3)tune config 的 过程会调用 do_bench 来多次调用 kernel 获得评估 config 的时间
cache
triton cache默认存在~/.triton/cache/文件夹下,当然也可以使用export TRITON_CACHE_DIR=xxx来指定。
triton 是 jit 的执行模式,但为了减少编译时间,其实会保留每次编译得到的 kernel,所以真实的编译流程是:
1.根据 kernel 信息生成一个 metadata_filename(一个 json 文件),然后在cache目录中查找
1
2
3
4
if not always_compile and metadata_path is not None:
# cache hit!
metadata = json.loads(Path(metadata_path).read_text())
return CompiledKernel(src, metadata_group, hash) # hash
2.如果找到了就用,没找到就需要编译
python->ast->ttir->…
1
2
3
4
5
6
7
8
9
10
11
12
├── 1e888eeebd0dc80dd6656c3193fb8376020f69d0e3b0b3f8a540f22c12357303
│ ├── _attn_fwd.cubin
│ ├── _attn_fwd.json
│ ├── _attn_fwd.llir
│ ├── _attn_fwd.ptx
│ ├── _attn_fwd.ttgir
│ ├── _attn_fwd.ttir
│ └── __grp___attn_fwd.json
├── 41ce1f58e0a8aa9865e66b90d58b3307bb64c5a006830e49543444faf56202fc
│ └── cuda_utils.so
└── 72d7b51280ef4fc8848331fd56d843a8a4deab4657a8767807c06728dbc23691
└── __triton_launcher.so
3.某个op多次执行,什么时候会hit cache,什么时候需要重新编译呢?
这需要从 triton 何时会产生一个新 cache 讲起。 triton 会以 key 为核心,key 包含 sig_and_spec, constexpr_vals 和 excess_kwargs。
sig_and_spec: 函数名 和 参数类型(一般是ptr/正整数/constexpr类型),直接表现在 kernel 上。当参数类型很多的时候也可以使用do_not_specialize来排除掉某些参数的影响,来避免生成更多的 kernel。constexpr_vals: 标记为tl.constexpr的参数excess_kwargs:num_stages,num_warps等
缓存 autotune 中性能最好的 config 生成的 kernel。当 key 改变时就会重新编译,也可以设置 TRITON_ALWAYS_COMPILE=1 来强制编译。
-> tune config 个数增加,也会触发重新编译,因为要对新增的 config 进行性能衡量(tune的过程会对每一条config调用do_bench)
backend
launch
由于每个 kernel 的参数可能不同,所以需要为其生成不同的执行函数,会使用 kernel 的一些信息和固定的代码拼接。最终变成一个可以调以调用的接口。
triton-lang elements
这里只是简单介绍下,举个🌰,vector add
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
import torch
import triton
import triton.language as tl
# 这是kernel
@triton.jit
def add_kernel(x_ptr, # *Pointer* to first input vector.
y_ptr, # *Pointer* to second input vector.
output_ptr, # *Pointer* to output vector.
n_elements, # Size of the vector.
BLOCK_SIZE: tl.constexpr, # Number of elements each program should process.
# NOTE: `constexpr` so it can be used as a shape value.
):
# There are multiple 'programs' processing different data. We identify which program
# we are here:
pid = tl.program_id(axis=0) # We use a 1D launch grid so axis is 0.
# This program will process inputs that are offset from the initial data.
# For instance, if you had a vector of length 256 and block_size of 64, the programs
# would each access the elements [0:64, 64:128, 128:192, 192:256].
# Note that offsets is a list of pointers:
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# Create a mask to guard memory operations against out-of-bounds accesses.
mask = offsets < n_elements
# Load x and y from DRAM, masking out any extra elements in case the input is not a
# multiple of the block size.
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
# Write x + y back to DRAM.
tl.store(output_ptr + offsets, output, mask=mask)
# 这是launch函数
def add(x: torch.Tensor, y: torch.Tensor):
# We need to preallocate the output.
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
# The SPMD launch grid denotes the number of kernel instances that run in parallel.
# It is analogous to CUDA launch grids. It can be either Tuple[int], or Callable(metaparameters) -> Tuple[int].
# In this case, we use a 1D grid where the size is the number of blocks:
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
# NOTE:
# - Each torch.tensor object is implicitly converted into a pointer to its first element.
# - `triton.jit`'ed functions can be indexed with a launch grid to obtain a callable GPU kernel.
# - Don't forget to pass meta-parameters as keywords arguments.
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
# We return a handle to z but, since `torch.cuda.synchronize()` hasn't been called, the kernel is still
# running asynchronously at this point.
return output
input
- pointer
x_ptr, y_ptr 指针,为其代表的tensor的第一个元素的地址。用来将数据load到memory
- hyper-parameter
超参数 tl.constexptr ,运行时传入的值来自 compiler 搜索得到。对于不同的硬件使用时,最佳性能(访存+计算)的参数可能是不同的,后续由 Triton compiler 来进行搜索不同的值
- stride
输入中一般也有stride,对于n维的tensor a,a.stride()会输出一个n维数组。stride用来找每个元素的指针
pid
一个 job 被分成 grid 个 task。pid = tl.program_id(axis=0) 表示当前是第几个task
- program_id是这个虚拟的for 循环 里面的 index (第几次循环,实际中这些循环是并行)
1
2
3
4
5
6
7
pid = tl.program_id(axis=0)
# 当访问数据总长256, BLOCK_SIZE=64
# tl.arange(0, BLOCK_SIZE) -> [0, 63]
# 0, 64, 128, 192
block_start = pid * BLOCK_SIZE
# 所以数据访问时是按照 [0:64, 64:128, 128:192, 192:256]
offsets = block_start + tl.arange(0, BLOCK_SIZE)
axis, 是说明 “循环”有几层,此处 axis = 0表示展开为1维来访问
axis是启动3d Grid的索引,必须是0 / 1 / 2
load & store
显示地load和store,批量数据处理,以BLOCK为单位,一次处理一个BLOCK_SIZE的数据,SIMD行为
load:从DRAM读到SRAM;store:从SRAM写回DRAM;减少了DRAM上计算行为。load和store在语义上可以解释为gather和scatter
1
2
3
4
5
# load 和 store 时都是使用基地址加偏移 获得一片数据,mask表示只获得这片数据中的一部分
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
# 写回时也需要mask
tl.store(output_ptr + offsets, output, mask=mask)
- offsets
offsets 为要处理数据的范围,由当前block_start和range计算而成
1
2
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
- mask
mask 为遮盖,类似decoder Attn中的mask。一是规范访存行为,防止越界(最后一块数据大小可能不满足防止 BLOCK_SIZE 的大小);二是过滤对本次计算不必须的数据。
例如offset=1024,mask为一个1024维的数组,每个数为0/1,当某位为1时,则load该数据,当某位为0时,舍弃。
算法精度误差有可能就是 mask 的设定存在问题
grid
调用kernel时,需要说明该kernel执行循环有几层,每层有几次,这就是 grid 的概念
以Matmul而言,若A为MxK,B为KxN,那么C的大小就是MxN(M和N为parallel axis大小,K为reduction轴大小)
每次分块计算,单块大小BLOCK_SIZE_M x BLOCK_SIZE_N,总共进行
\[\frac{M}{\text{BLOCK\_{SIZE}\_{M}}} \times \frac{N}{\text{BLOCK\_{SIZE}\_{N}}}\]Triton中关于grid定义:
1
2
3
4
5
6
7
8
9
10
11
grid = lambda META: (
triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),
)
matmul_kernel[grid](
a, b, c,
M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
ACTIVATION=activation
)
对比Cuda中launch kernel的行为
1
2
3
dim3 block(BLOCK_SIZE_M, BLOCK_SIZE_N);
dim3 grid((M + BLOCK_SIZE_M - 1) / BLOCK_SIZE_M, (N + BLOCK_SIZE_N - 1) / BLOCK_SIZE_N);
matmul_kernel<<<grid,block>>>(Ad, Bd, Cd, M, N, K);
num_warp
一般体现在module Attr上,下面的代码意味着这个程序使用4个warp执行(这个参数一般也是 tl.constexpr)
1
"triton_gpu.num-warps" = 4 : i32
tritongpu ir相比ttir仅多了一个Blocked Layout,本质上描述的是Block对Memory的Access Pattern
1
#blocked = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
就是一个CTA里有4个Warp,一个Warp有32个Thread,一个Thread处理1个元素。
Blocked Layout只是一种Pattern,但按照这个Pattern会多次访问,总访问量达到BLOCK_SIZE
num_stages
控制软件流水展开级数
triton中的流水位于TritonGPU/Transforms/Pipeliner。
Triton 中并不需要很复杂的软件流水
- grid一般写成(M/BLOCK_SIZE, 1, 1),每个job内的数据量较小
- SM中的 warp-schedule 起到了一些流水的效果:当warp执行一个long-latency的指令时,会通过切换warp掩盖指令开销
- NV在新架构中引入了
cp.async指令,gdram -> shared memory 的拷贝可以通过DMA异步进行 -> 所以需要软件流水来优化load的行为,让循环内的load尽量可以异步
-> 只需要考虑load情况,计算和访存流水靠warp scheduler这一层来处理
一个matmul的计算表示ir
1
2
3
4
scf.for %arg0 = %c0 to %size step %c1 {
load.sync A & B
dot A, B
}
当num_stagses = 2的时候,相当于会提前加载一个iter的数据,也就是变成如下代码:
1
2
3
4
5
6
7
8
9
load.async A0, B0
async_wait
scf.for %arg0 = %c1 to %size-1 step %c1 { %arg0=A0, %arg1=B0 }{
dot arg0, arg1
addptr Anext, Bnext
load.async Anext, Bnext
async_wait
}
async_wait
流水中使用的一些ir
- triton_gpu.alloc_tensor : tensor<128x32xf32, #share> 申请shared memory
- triton_gpu.insert_slice_async %src, %dst, %index : tensor<128x32x!tt.ptr
> → tensor<128x32xf32, #share> 底层对应的cp.async指令 - %src: 数据地址,也就是tensor<128x32x!tt.ptr
> - %dst: 申请的shared memory
- %index: 从src加载的数据插入到%dst的目标索引
- %src: 数据地址,也就是tensor<128x32x!tt.ptr
- triton_gpu.async_commit_group 底层对应的 cp.async.commit_group 指令,就是将前面的所有 cp.async 指令打包到一起执行
- triton_gpu.async_wait {num} 底层对应的 cp.async.wait_group 指令,也就是等待前面 num 个 cp.async-groups 执行完
trick
不同的环境变量
MLIR_ENABLE_DUMP=1
dumps the IR before every MLIR pass Triton runs
TRITON_PRINT_AUTOTUNING=1
打印每次选择的 config
TRITON_INTERPRET=1
适用 numpy 解释执行,直接变成一个cpu kernel,用来验证算法的准确性。
可以方便地使用 pdb 和 print,针对 load 和 store 都重新实现了,但不支持 atomic,不支持多级指针(!tt.ptr<!tt.ptr<f32>>)。
TRITON_PRINT_AUTOTUNING=1
打印每次 tuning 中的最优 tuning config 和 耗时。
TRITON_DISABLE_LINE_INFO=1
关闭 dump ir 中的 loc info
打印pass前后ir
- 使用
triton-opt直接跑 pipeline,加上mlir-print-ir-after-all - 改 python 中 triton 库
site-packages/triton/backend/xxx/compiler.py中的代码,例如注释掉下面某个pass来看ir是否不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# /usr/lib/python3.10/site-packages/triton/backends/xxx/compiler.py
def make_ttir(mod, metadata, opt):
pm = ir.pass_manager(mod.context)
pm.enable_debug()
passes.common.add_inliner(pm)
passes.ttir.add_rewrite_tensor_pointer(pm)
passes.ttir.add_combine(pm)
passes.common.add_canonicalizer(pm)
passes.ttir.add_reorder_broadcast(pm)
passes.common.add_cse(pm)
passes.common.add_licm(pm)
passes.common.add_symbol_dce(pm)
pm.run(mod)
return mod
优化
常见方法
1.调整tuning config
先把粒度调细,确定当前任务规模的最优性能大致选择的tuning config,再写减枝函数。
- 调整拆分大小:BLOCK_SIZE
- num_stages调整流水级数
2.修改kernel实现
- 每个算子的理论计算量是固定的,一般都是有冗余的IO。
- 多用make_tensor_ptr,产生
!tt.ptr<tensor<xxxx>>,直接是一片连续的数字
3.添加新的下降pattern
一般涉及不到。elementwise(broadcast(a), broadcast(b)) -> broadcast(elementwise(a, b))
示例
1.修改算法,减少load数量
layernorm的正向计算:load一次计算mean,再load一次计算var -> var = sum(x^2) / n - x_hat^2 一次计算mean和var
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@triton.jit
def _layer_norm_fwd_fused(
...
mean = 0
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
_mean += a
mean = tl.sum(_mean, axis=0) / N
# Compute variance
_var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
x = tl.where(cols < N, x - mean, 0.)
_var += x * x
var = tl.sum(_var, axis=0) / N
rstd = 1 / tl.sqrt(var + eps)
...
var = sum((x - mean)^2) -> var = sum(x^2) / n - mean^2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Optimized Implementation.
@triton.jit
def _layer_norm_fwd_fused_with_small_n(
...
# Compute mean and variance
mean = 0
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
_x_square = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
_mean += a
_x_square += a * a
mean = tl.sum(_mean, axis=1) / N
var = tl.sum(_x_square, axis=1) / N - mean * mean
rstd = 1 / tl.sqrt(var + eps)
...
2.合并kernel,调节config
例:来源:flaggems/vector_norm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@triton.jit
def min_norm_kernel_1(X, Mid, M, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
X = X + offset
Mid = Mid + pid
mask = offset < M
x = tl.load(X, mask=mask, other=float("inf")).to(tl.float32)
mid = tl.min(tl.abs(x))
tl.store(Mid, mid)
@triton.jit
def min_norm_kernel_2(Mid, Out, MID_SIZE, BLOCK_MID: tl.constexpr):
offset = tl.arange(0, BLOCK_MID)
Mid = Mid + offset
mask = offset < MID_SIZE
mid = tl.load(Mid, mask=mask, other=float("inf")).to(tl.float32)
out = tl.min(mid)
tl.store(Out, out)
# 传入kernel的参数
BLOCK_SIZE = triton.next_power_of_2(math.ceil(math.sqrt(M)))
MID_SIZE = triton.cdiv(M, BLOCK_SIZE) # grid
BLOCK_MID = triton.next_power_of_2(MID_SIZE)
mid = torch.empty([MID_SIZE], dtype=dtype, device=x.device)
out = torch.empty(shape, dtype=dtype, device=x.device)
min_norm_kernel_1[(MID_SIZE,)](x, mid, M, BLOCK_SIZE)
min_norm_kernel_2[(1,)](mid, out, MID_SIZE, BLOCK_MID)
->
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
def cfggen_reduce_op():
block_size = [1024, 2048, 4096, ...]
num_stage = [...]
configs=[
triton.Config({"BLOCK_SIZE": m}, num_warps=4, num_stages=s) for m in block_size for s in num_stage
]
return configs
def prune_reduce_config(configs, named_args, **kwargs):
M = named_args["M"]
pruned_configs = []
for config in configs:
BLOCK_SIZE = config.kwargs["BLOCK_SIZE"]
num_stages = config.num_stages
num_block = M // BLOCK_SIZE
...
if (len(pruned_configs) == 0):
pruned_configs.append(triton.Config({"BLOCK_SIZE": next_power_of_two(M)}, num_warps=4, num_stages=1))
return pruned_configs
@triton.autotune(
configs=cfggen_reduce_op(),
key=["M"],
prune_configs_by={'early_config_prune': prune_reduce_config}
)
@triton.jit
def min_norm_kernel(
X,
Out,
M,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < M
x = tl.load(X + offsets, mask, other=0.0).to(tl.float32)
mid = tl.min(tl.abs(x))
tl.atomic_min(Out, mid.to(tl.float32))
# 传入kernel的参数
grid = lambda meta: (triton.cdiv(M, meta['BLOCK_SIZE']), )
out = torch.zeros(shape, dtype=torch.float, device=x.device)
min_norm_kernel_1[grid](x, out, M)
3.common:LICM,减少跳转开销
改进写法要减少 H*W - 1次跳转开销
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
for i in range(H):
for j in range(W):
if (a > b):
compute1()
else:
compute2()
->
if (a > b):
for i in range(H):
for j in range(W):
compute1()
else:
for i in range(H):
for j in range(W):
compute2()
IR
triton python 语言是python的一个子集,它通过ast 模块解析python代码,生成一个python 语法树。
遍历整个语法树的过程,通过code_generator相关代码,定义visit_Assign等函数,通过mlir builder生成对应的mlir(ttir)。然后ttir继续走 mlir pipeline继续下降。
添加一种新原语
参考:Implement scaled_dot(mxfp8, fp8) via mma
dot_scaled -> semantic.dot_scaled -> tl.tensor(builder.create_dot_scaled(…))
1.python/triton/language/core.py 中注册该原语,return部分会调用到 semantic 中
2.python/triton/language/semantic.py 描述了该原语创建 ir 的行为,例如对operand进行 broadcast 或 splat
3.python/src/ir.cc 创建triton dialect op(tt.op)
4.添加后续conversion(ttir->ttgir->llvmir)
AxisInfo
AxisInfo 会对 load、store 等对指针进行操作的 op 及相关 op 进行跟踪,分析出 divisibility, contiguity, constancy 信息,从而辅助之后的 pass 进行,以获得高 IO 效率。
- divisibility:维度i上,所有元素的最大二次幂公约数。该值用来表示指针地址的对齐,指导后续访存操作的下降
- contiguity:维度i上,连续元素的最小长度,说明至少每contiguity[i]个元素是连续的
- constancy:维度i上,重复元素的最小长度,说明至少每constancy[i]个元素是重复的
- constantValue:表示值为常数,一般信息源头来自
arith.constant
利用这些信息可以优化放存行为:
- 当 load 16x256 个数时,若低维每 256 个数重复,那么可以只 load 16 个数据,再 broadcast 成 16x256。
- mask全为true或false时可以转为 scf.if + load,反之也可以优化为
select %mask, %load, %other
可以通过 test-print-alignment pass 来打印 AnisInfo,详见 TestAxisInfo
layout
TritonGPU Dialect 这一层的 IR的 tensor 表示将带有 Layout 的 Attr,该 Attr 定义了 Data 是如何被 Thread 并行处理。这种layout attr在lowering过程中被传递。
自 [RFC] To generalize TritonGPU dialect for GPU of different vendors 后, TritonGPU Dialect 中的 Layout Attribute 正式统一为下图:
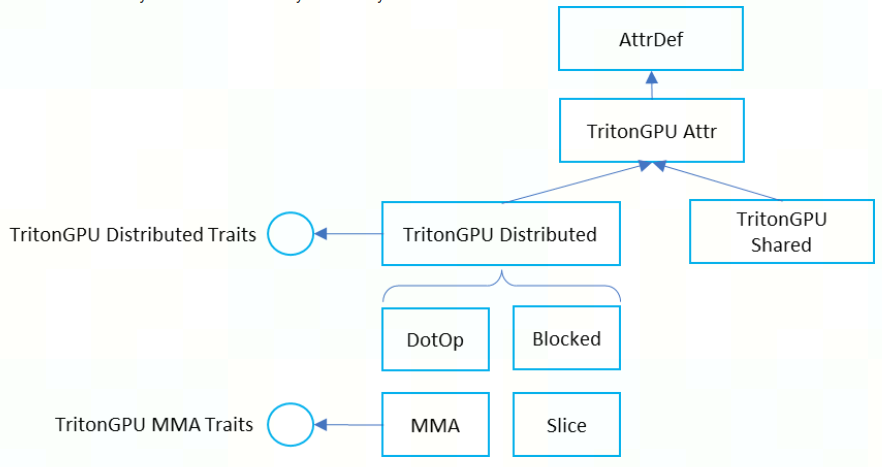
当前最重要的也是 distributed layout 和 shared layout。
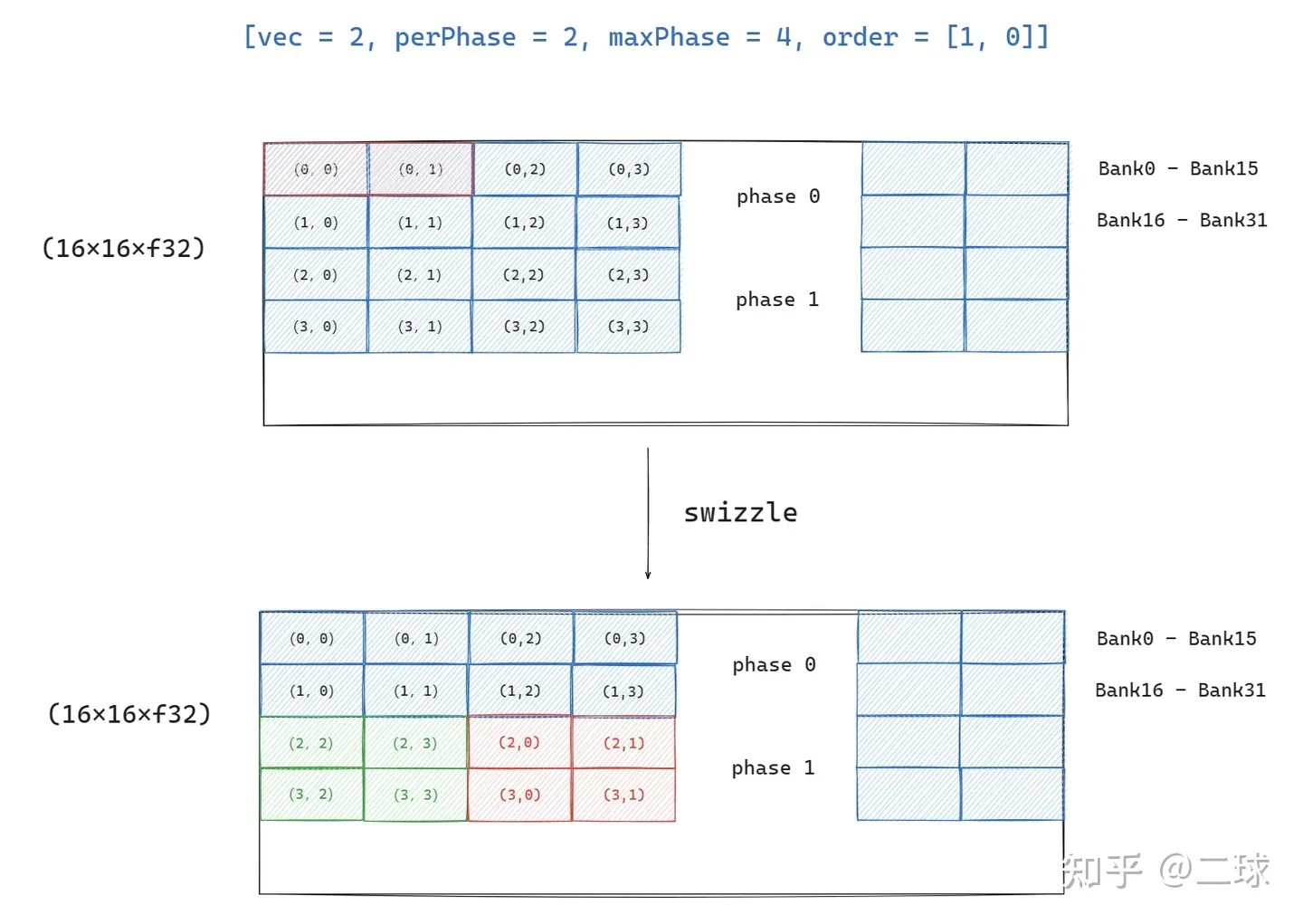
shared layout
表示了一种 tensor 编码模式,用于指导如何进行 swizzle,使得不同 thread 在访问 tensor(on shared memory) 上的元素时尽量避免 bank conflict。
swizzle:调整数据在 shared memory 上的存储位置,保证 thread 访问时不出现 bank conflict。
该layout中主要对象为:
- vec:同行的元素进行swizzle时,连续vec个为一组
- perPhase:一次 swizzling phase 处理的 row 数。连续的 perPhase 行用相同的swizzle方法
- maxPhase:swizzling phase的个数
- order:表明哪一个为主序,[1, 0] 为行主序,同行相邻元素地址连续
- hasLeadingOffset:默认为false,Hopper MMAv3为true
swizzle 最基础的方法就是地址 与 phase_id 进行 xor。
假设现在有4x4个元素需要存到 shared memory 上去,存放的初始地址为:
[r, c] 上对应的元素为 (r:c)。
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)]
[ (1:0),(1:1),(1:2),(1:3)]
[ (2:0),(2:1),(2:2),(2:3)]
[ (3:0),(3:1),(3:2),(3:3)]]
- #shared<{vec=1, perPhase=1, maxPhase=4, order=[1,0]}>
不同行中的地址与不同的参数 xor。out[r][c] = in[r][c ^ r]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0 (xor with 0)
[ (1:1),(1:0),(1:3),(1:2)] // phase 1 (xor with 1)
[ (2:2),(2:3),(2:0),(2:1)] // phase 2 (xor with 2)
[ (3:3),(3:2),(3:1),(3:0)]] // phase 3 (xor with 3)
- #shared<{vec=1, perPhase=2, maxPhase=4, order=[1,0]}>
相邻 2 (perPhase) 行中的地址用相同的参数xor。out[r][c] = in[r][c ^ (r / 2)]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)] // phase 0 (xor with 0)
[ (1:0),(1:1),(1:2),(1:3)] // phase 0 (xor with 0)
[ (2:1),(2:0),(2:3),(2:2)] // phase 1 (xor with 1)
[ (3:1),(3:0),(3:3),(3:2)]] // phase 1 (xor with 1)
- #shared<{vec=2, perPhase=2, maxPhase=4, order=[1,0]}>
相邻 2(vec) 元素为一组,进行 xor。out[r][c] = in[r][(c / 2) ^ (r % 2)) * 2 + (c % 2)]
1
2
3
4
[[(0:0),(0:1),(0:2),(0:3)]
[ (1:0),(1:1),(1:2),(1:3)]
[ (2:2),(2:3),(2:0),(2:1)]
[ (3:2),(3:3),(3:0),(3:1)]]
distributed layout
distributed layout 使用映射函数描述整个 tensor 的访问模式。映射函数(layout function)会将特定的Tensor交给特定的Thread去处理(即一个layout描述整个tensor的访问模式),达到一个distribution的效果
distributte layout 将信息分为4个维度:
- CTAs Per CGA:在 hopper 上才有用,因为 hopper 架构首次引入了 SM-to-SM
- Warps Per CTA:CTA 内 warp 的布局(对应
warpsPerCTA) - Threads Per Warp:warp 内 thread 的布局(对应
threadsPerWarp) - Values Per Thread:一个 thread 需要处理多少元素(对应
sizePerThread)
block layout
最常见的 layout,结合 AxisInfoAnalysis 获得 load 和 store 的访存行为,再用来访存合并(memory coalescing),使得访存行为更加高效。
An encoding where each warp owns a contiguous portion of the target tensor. This is typically the kind of data layout used to promote memory coalescing in LoadInst and StoreInst.
- 基础概念
例如:#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
- sizePerThread = [1, 4]:每个线程处理的 连续排布 数据数目
- threadsPerWarp = [4, 8]: warp内线程的布局
- warpsPerCTA = [1, 1]:thread block内warp的布局
- order = [1, 0]:先访问dim1,再访问dim0
该BLock访存模式:每行由8个thread负责访问,每个thread会访问连续4个元素,所以一次能处理(1x4x1, 8x4x1) = (4, 32)规模的shape。如下:
1
2
3
4
5
6
7
$ triton-tensor-layout -l "#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>" -t "tensor<4x32xf16>"
# T0:0, T0:1, T0:2, T0:3 表示 T0 一次处理4个连续数组成的块
Print layout attribute: #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
[[ T0:0, T0:1, T0:2, T0:3, T1:0, T1:1, T1:2, T1:3, T2:0, T2:1, T2:2, T2:3, T3:0, T3:1, T3:2, T3:3, T4:0, T4:1, T4:2, T4:3, T5:0, T5:1, T5:2, T5:3, T6:0, T6:1, T6:2, T6:3, T7:0, T7:1, T7:2, T7:3]
[ T8:0, T8:1, T8:2, T8:3, T9:0, T9:1, T9:2, T9:3, T10:0, T10:1, T10:2, T10:3, T11:0, T11:1, T11:2, T11:3, T12:0, T12:1, T12:2, T12:3, T13:0, T13:1, T13:2, T13:3, T14:0, T14:1, T14:2, T14:3, T15:0, T15:1, T15:2, T15:3]
[ T16:0, T16:1, T16:2, T16:3, T17:0, T17:1, T17:2, T17:3, T18:0, T18:1, T18:2, T18:3, T19:0, T19:1, T19:2, T19:3, T20:0, T20:1, T20:2, T20:3, T21:0, T21:1, T21:2, T21:3, T22:0, T22:1, T22:2, T22:3, T23:0, T23:1, T23:2, T23:3]
[ T24:0, T24:1, T24:2, T24:3, T25:0, T25:1, T25:2, T25:3, T26:0, T26:1, T26:2, T26:3, T27:0, T27:1, T27:2, T27:3, T28:0, T28:1, T28:2, T28:3, T29:0, T29:1, T29:2, T29:3, T30:0, T30:1, T30:2, T30:3, T31:0, T31:1, T31:2, T31:3]]
但若输入op的shape为(8, 32),那么让每个thread处理两个连续块即可,即第一个thread处理(0, 0:3), (4, 0:3)两个块。
MMA Layout 和 DotOperand Layout
用来指导 op 下降到特殊指令的 attr。
1.MMA Layout
表示 Tensor Core 中 MMA 指令结果的 data layout,一般可以直接对应到 PTX 指令中相应的数据排布需求。
和硬件相关很大,这里不展开
2.DotOperand Layout
表示 dotOp 的输入的 layout。主要包含 opIdx 和 parent 两个信息,
- opIdx :用来标识 dotOp 的操作数
- opIdx=0 表示 DotOp 的 $a
- opIdx=1 表示 DotOp 的 $b
- parent:决定了 DotOperand 的布局方式
- MMA Layout(如果 DotOp lower 到 MMA 指令)
- Blocked Layout(如果 DotOp lower 到 FMA 指令)
tools for layout
在 PR 中合入了一个可以打印 ttgir 上 layout 的工具 triton-tensor-layout,通过调用 getLayoutStr 来解析 RankedTensorType 中的 layout 信息,且当前已经支持了 shared layout 的 dump。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ triton-tensor-layout -l "#triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>" -t "tensor<16x16xf16>"
Print layout attribute: #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
# 每行用8个thread,每行中每个thread会负责连续的4个元素,但一行只有16个元素,所以4个thread就能遍历完一遍了
# 因此 T0 和 T4 都会访问第0行的前四个元素
[[ T0:0| T4:0, T0:1| T4:1, T0:2| T4:2, T0:3| T4:3, T1:0| T5:0, T1:1| T5:1, T1:2| T5:2, T1:3| T5:3, T2:0| T6:0, T2:1| T6:1, T2:2| T6:2, T2:3| T6:3, T3:0| T7:0, T3:1| T7:1, T3:2| T7:2, T3:3| T7:3]
[ T8:0| T12:0, T8:1| T12:1, T8:2| T12:2, T8:3| T12:3, T9:0| T13:0, T9:1| T13:1, T9:2| T13:2, T9:3| T13:3, T10:0| T14:0, T10:1| T14:1, T10:2| T14:2, T10:3| T14:3, T11:0| T15:0, T11:1| T15:1, T11:2| T15:2, T11:3| T15:3]
[ T16:0| T20:0, T16:1| T20:1, T16:2| T20:2, T16:3| T20:3, T17:0| T21:0, T17:1| T21:1, T17:2| T21:2, T17:3| T21:3, T18:0| T22:0, T18:1| T22:1, T18:2| T22:2, T18:3| T22:3, T19:0| T23:0, T19:1| T23:1, T19:2| T23:2, T19:3| T23:3]
[ T24:0| T28:0, T24:1| T28:1, T24:2| T28:2, T24:3| T28:3, T25:0| T29:0, T25:1| T29:1, T25:2| T29:2, T25:3| T29:3, T26:0| T30:0, T26:1| T30:1, T26:2| T30:2, T26:3| T30:3, T27:0| T31:0, T27:1| T31:1, T27:2| T31:2, T27:3| T31:3]
[ T32:0| T36:0, T32:1| T36:1, T32:2| T36:2, T32:3| T36:3, T33:0| T37:0, T33:1| T37:1, T33:2| T37:2, T33:3| T37:3, T34:0| T38:0, T34:1| T38:1, T34:2| T38:2, T34:3| T38:3, T35:0| T39:0, T35:1| T39:1, T35:2| T39:2, T35:3| T39:3]
[ T40:0| T44:0, T40:1| T44:1, T40:2| T44:2, T40:3| T44:3, T41:0| T45:0, T41:1| T45:1, T41:2| T45:2, T41:3| T45:3, T42:0| T46:0, T42:1| T46:1, T42:2| T46:2, T42:3| T46:3, T43:0| T47:0, T43:1| T47:1, T43:2| T47:2, T43:3| T47:3]
[ T48:0| T52:0, T48:1| T52:1, T48:2| T52:2, T48:3| T52:3, T49:0| T53:0, T49:1| T53:1, T49:2| T53:2, T49:3| T53:3, T50:0| T54:0, T50:1| T54:1, T50:2| T54:2, T50:3| T54:3, T51:0| T55:0, T51:1| T55:1, T51:2| T55:2, T51:3| T55:3]
[ T56:0| T60:0, T56:1| T60:1, T56:2| T60:2, T56:3| T60:3, T57:0| T61:0, T57:1| T61:1, T57:2| T61:2, T57:3| T61:3, T58:0| T62:0, T58:1| T62:1, T58:2| T62:2, T58:3| T62:3, T59:0| T63:0, T59:1| T63:1, T59:2| T63:2, T59:3| T63:3]
[ T64:0| T68:0, T64:1| T68:1, T64:2| T68:2, T64:3| T68:3, T65:0| T69:0, T65:1| T69:1, T65:2| T69:2, T65:3| T69:3, T66:0| T70:0, T66:1| T70:1, T66:2| T70:2, T66:3| T70:3, T67:0| T71:0, T67:1| T71:1, T67:2| T71:2, T67:3| T71:3]
[ T72:0| T76:0, T72:1| T76:1, T72:2| T76:2, T72:3| T76:3, T73:0| T77:0, T73:1| T77:1, T73:2| T77:2, T73:3| T77:3, T74:0| T78:0, T74:1| T78:1, T74:2| T78:2, T74:3| T78:3, T75:0| T79:0, T75:1| T79:1, T75:2| T79:2, T75:3| T79:3]
[ T80:0| T84:0, T80:1| T84:1, T80:2| T84:2, T80:3| T84:3, T81:0| T85:0, T81:1| T85:1, T81:2| T85:2, T81:3| T85:3, T82:0| T86:0, T82:1| T86:1, T82:2| T86:2, T82:3| T86:3, T83:0| T87:0, T83:1| T87:1, T83:2| T87:2, T83:3| T87:3]
[ T88:0| T92:0, T88:1| T92:1, T88:2| T92:2, T88:3| T92:3, T89:0| T93:0, T89:1| T93:1, T89:2| T93:2, T89:3| T93:3, T90:0| T94:0, T90:1| T94:1, T90:2| T94:2, T90:3| T94:3, T91:0| T95:0, T91:1| T95:1, T91:2| T95:2, T91:3| T95:3]
[ T96:0|T100:0, T96:1|T100:1, T96:2|T100:2, T96:3|T100:3, T97:0|T101:0, T97:1|T101:1, T97:2|T101:2, T97:3|T101:3, T98:0|T102:0, T98:1|T102:1, T98:2|T102:2, T98:3|T102:3, T99:0|T103:0, T99:1|T103:1, T99:2|T103:2, T99:3|T103:3]
[ T104:0|T108:0, T104:1|T108:1, T104:2|T108:2, T104:3|T108:3, T105:0|T109:0, T105:1|T109:1, T105:2|T109:2, T105:3|T109:3, T106:0|T110:0, T106:1|T110:1, T106:2|T110:2, T106:3|T110:3, T107:0|T111:0, T107:1|T111:1, T107:2|T111:2, T107:3|T111:3]
[ T112:0|T116:0, T112:1|T116:1, T112:2|T116:2, T112:3|T116:3, T113:0|T117:0, T113:1|T117:1, T113:2|T117:2, T113:3|T117:3, T114:0|T118:0, T114:1|T118:1, T114:2|T118:2, T114:3|T118:3, T115:0|T119:0, T115:1|T119:1, T115:2|T119:2, T115:3|T119:3]
[ T120:0|T124:0, T120:1|T124:1, T120:2|T124:2, T120:3|T124:3, T121:0|T125:0, T121:1|T125:1, T121:2|T125:2, T121:3|T125:3, T122:0|T126:0, T122:1|T126:1, T122:2|T126:2, T122:3|T126:3, T123:0|T127:0, T123:1|T127:1, T123:2|T127:2, T123:3|T127:3]]
pytorch-to-triton
pytorch代码通过 torch.compile 可以产生 triton kernel。 torch.compile 可以使用多种 backend,例如 eager、inductor(默认) 等。
下面是一个从 pytorch 代码转到 triton kernel 的例,利用了 triton.compile(backend="indunctor")。
- 输入: test_add.py
1
2
3
4
5
6
7
8
9
10
import torch
def func(in1, in2):
return torch.add(in1, in2)
opt_fn = torch.compile(func)
a = torch.randn(100, 10480, device="cuda")
b = torch.randn(100, 10480, device="cuda")
opt_fn(a,b)
- 运行:
python test_add.py
在 /tmp/torchinductor_${USER} 下找到 triton code 以及 ttir
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/tmp/torchinductor_root# tree -L 3
.
|-- 5a # 包含__main__封装的函数调用行为
| `-- c5anvd6whgca2cpb7ukgizx5jlgxefgorn7ebtgxxtj2tm53rkom.py
|-- im # tuning 时的最优config 以及 生成的 triton kernel
| |-- cimktqodcpl2shgn3s6k3t3aa7m4b3dogeudqxny3cvpjkrmjjtx.best_config
| `-- cimktqodcpl2shgn3s6k3t3aa7m4b3dogeudqxny3cvpjkrmjjtx.py
`-- triton # compile cache
`-- 0
|-- 1801f53031fb6b10991a839c4c36f1ac09a877d0118cd6433bc1c4348b757831
|-- 3a61b614a201d7c8de1da696f6276c6469631a07e1c1112872fcde349e60acb2
|-- 83f4d801beeb824446d3ceb3e79e3e01bd3e2b91ab6fda189b715a72fcdf30e9
|-- 9bebfd64edaf8e09d00770860d8e8ced2ff88b1f9ed6d7f2338124d13cc915c7
|-- ae0c8a3e48147ccc432244a44fbd1d4793e58cd52158c26689f388047c187e97
|-- b4c72811b23880731310c2e71420ebfb89924cf8f93373f68d0baa43ee03cf67
`-- e6ab39b907a1a1838c7b1094681fe980548c7a9397404bba4b9daeb99b966266
其中生成的 triton kernel (triton-lang) 表示为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import triton
import triton.language as tl
from triton.compiler.compiler import AttrsDescriptor
from torch._inductor import triton_helpers, triton_heuristics
from torch._inductor.ir import ReductionHint, TileHint
from torch._inductor.triton_helpers import libdevice, math as tl_math
from torch._inductor.triton_heuristics import AutotuneHint
from torch._inductor.utils import instance_descriptor
@triton_heuristics.pointwise(
size_hints=[1048000],
filename=__file__,
triton_meta={'signature': {0: '*fp32', 1: '*fp32', 2: '*fp32', 3: 'i32'}, 'device': 0, 'device_type': 'cuda', 'constants': {}, 'configs': [AttrsDescriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]},
inductor_meta={'autotune_hints': set(), 'kernel_name': 'triton_poi_fused_add_0', 'mutated_arg_names': [], 'no_x_dim': False, 'backend_hash': '52964130331800C009CC77AD19A8AAFB702D8BB9B81D6B43FE21DEBE4B5B40E7'},
min_elem_per_thread=0
)
@triton.jit
def triton_poi_fused_add_0(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK : tl.constexpr, XBLOCK_FRAGMENT : tl.constexpr):
xnumel = 1048000
xoffset_num = tl.cdiv(XBLOCK, XBLOCK_FRAGMENT)
xstep = tl.num_programs(0) * XBLOCK_FRAGMENT
xoffset_begin = tl.program_id(0) * XBLOCK_FRAGMENT
for offset in range(xoffset_num):
xoffset = offset % xoffset_num * xstep + xoffset_begin
xindex = xoffset + tl.arange(0, XBLOCK_FRAGMENT)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = tl.load(in_ptr1 + (x0), xmask)
tmp2 = tmp0 + tmp1
tl.store(out_ptr0 + (x0), tmp2, xmask)
过程细节可以看:triton_heuristics.py
注册手写的 triton kernel:可以参考 flaggems 在 Aten 层面直接对算子进行覆盖重写,但这样就不是走 Inductor 了。 注册 Inductor 最简单的方式 compile 接口的 backend 直接指定一个 triton-lang 写好的 kernel。
dynamo到triton的桥梁,dynamo:通过eager模式生成一个图,inductor是把dynamo生成的graph变成kernel组合
torch.compile 后本质还是 eager 模式,只是通过 Inductor 将用户部分代码进行等价替换